
去年我們發布的《芯片設計五部曲》,還挺受歡迎的:
芯片設計五部曲之一 | 聲光魔法師——模擬IC
芯片設計五部曲之二 | 圖靈藝術家——數字IC
芯片設計五部曲之三 | 戰略規劃家——算法仿真
不少人輾轉問過我們下一集什么時候出。
放心,我們不鴿。
第四集這不就來了嘛,雖遲但到!

前幾集我們已經分別深入了模擬IC和數字IC的設計過程,展開了解了算法仿真的四大特性,以及結合EDA工具特性和原理,如何利用計算機技術提高模擬與數字芯片的研發設計效率。
就像我們在模擬IC篇講的:射頻芯片作為模擬電路王冠上的明珠,一直被認為是芯片設計中的“華山之巔”。隱藏在其設計過程中的取舍與權衡,完全值得單開一篇。
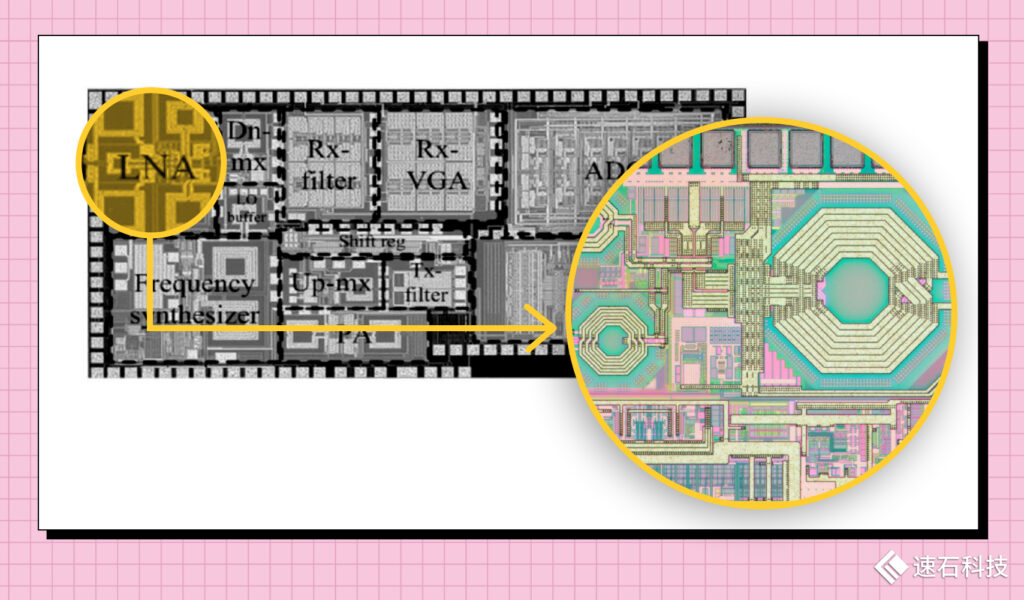
射頻芯片
不是你想象中的射頻芯片
射頻(Radio Frequency,簡寫RF),指用于無線電通信的頻率范圍,對應的電磁波頻率范圍在300kHz~300GHz之間。
射頻芯片(RFIC),指能接收或發射射頻信號并對其進行處理的集成電路,一般包括功率放大器(PA)、低噪聲放大器(LNA)、濾波器(Filter)、雙工器或多工器(Duplexer或Multiplexer)、開關(Switch)、天線調諧模塊(ASM)等。
RFIC應用領域有:移動通信、衛星通信、雷達系統、射頻識別(RFID)、傳感器等。
射頻電路,是一種特殊類型的模擬電路,是模擬電路在高頻領域的分支。
最早的射頻電路是通過昂貴的分立電路元件搭的,直到CMOS工藝實現了把所有器件集成在一片芯片上,提高了系統的集成度與性能,同時也降低了成本。
摩爾定律發展到后期,隨著電路和芯片復雜度提升,高頻下的電磁相互作用對射頻硬件的干擾開始引起了關注。信號反射、串擾和電磁干擾(EMI)以及元件自身的寄生效應(也叫寄生參數效應,是指在電路或系統中本來不希望存在但實際存在的一些額外參數或效應),會降低電路性能。
在低頻電子線路或者直流電路中,元器件的特性很一致。
而在高頻影響下,所有的器件都是電阻、電感和電容的組合,存在寄生參數。
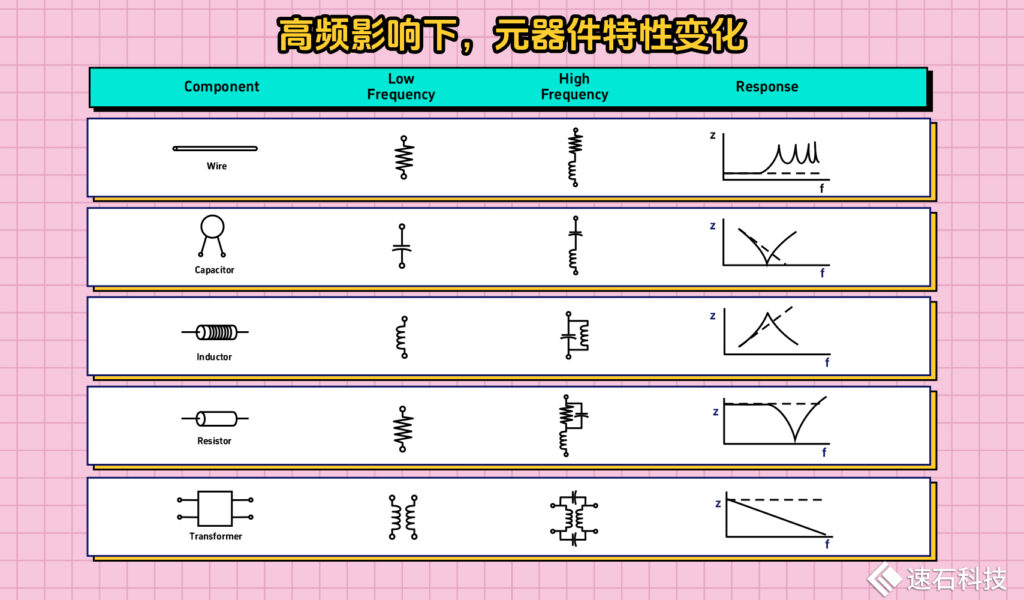
射頻電路中,理想的電阻、電容和電感在實際中并不存在。
電阻不是電阻、電容不是電容、電感不是電感、導線也不是導線。這些元器件都不是你想象中的元器件,不再只是一個簡單、孤立的物理器件,還包括了自身的材料特性、工藝,以及與周圍空間環境的交互。
頻率越高,影響越大。
以一根導線為例:
同樣一根導線,在射頻領域,導線不能被識別成導線,存在趨膚效應,即在頻率很高的時候,電流在導線內部不是均勻流動的,會集中在導線的表面,中心部分基本沒有電流通過。
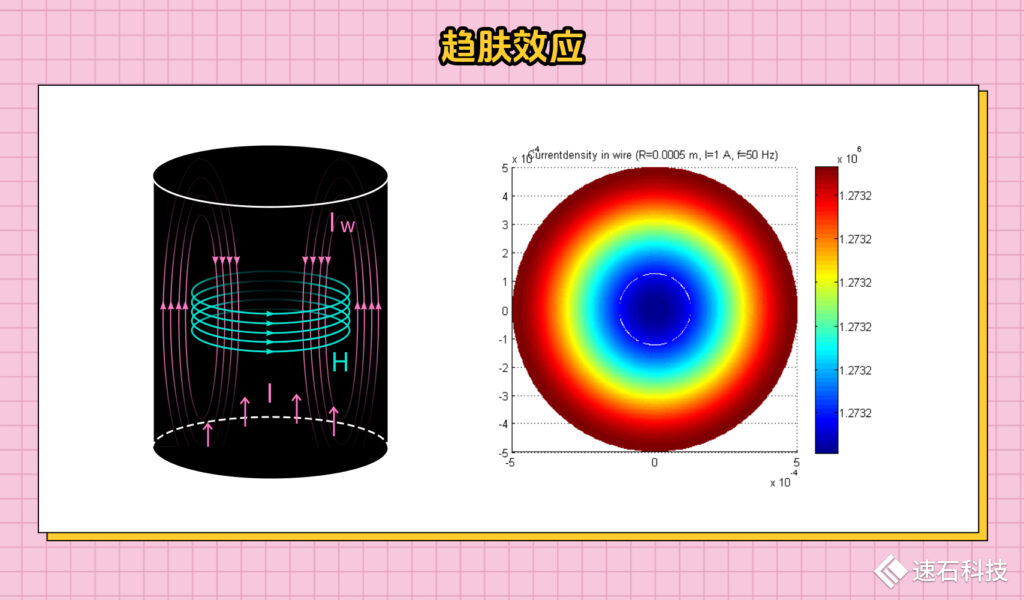
這是因為高頻電流通過的時候,在導線內部會產生一個軸向的交變磁場,該交變磁場會再度產生一個環形的徑向交變電場,該電場對導線外層電流進行加強,與內層電流相抵消,從而導致導線傳輸電流時,電流聚集在導線外層,而內層“空心化”使得整體效率減低,耗費金屬資源。
這時候,需要根據不同的頻率去考慮電流在導線里面的分布情況。
因此,射頻芯片的設計不能僅僅針對元器件本身建立數學模型,還需要針對高頻情況下的整個三維電磁環境做電磁學建模仿真。
隨著電子技術的發展,電路的集成度和工作頻率不斷提高,如何利用更先進的電磁場仿真技術,精確預測和分析寄生參數對電路性能的影響,是射頻設計工程師們的重要課題之一。
射頻IC設計 VS 模擬IC設計
看起來只差一步,其實大不相同
一顆射頻芯片的完整設計流程如下:
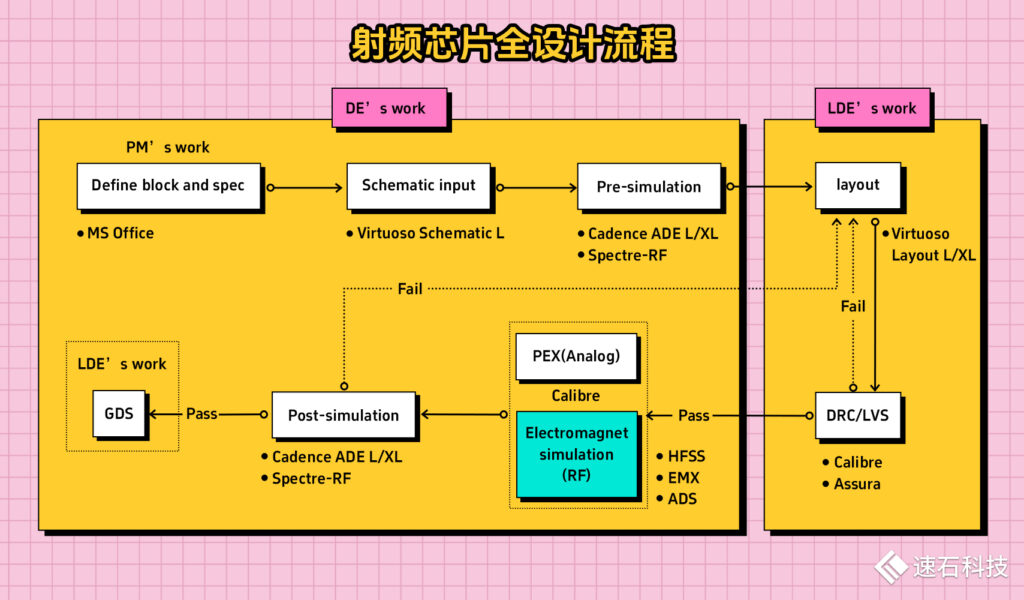
跟模擬芯片相比,主要是多了電磁仿真這一過程。
看起來只多了一小步,但卻是芯片設計工程師們的一大步。
01、工程師知識與能力儲備
射頻工程師和模擬工程師,是從同一根技能樹上生長出來的。
但是,大家都說,射頻工程師做模擬沒問題,反過來就不行。
為啥?
從知識儲備角度
模擬工程師主要學習模擬集成電路、信號系統與高數/物理相關知識。
射頻工程師除了模擬相關知識之外,還需要專門學習射頻集成電路、電磁場與通信原理等課程。
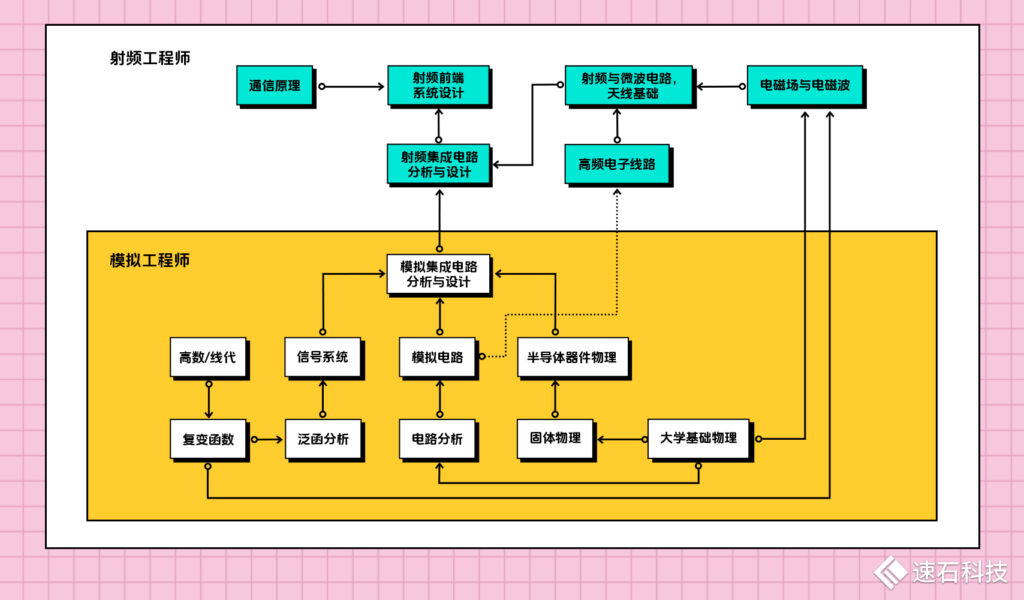
有人問過射頻芯片界大神——UCLA的Asad.A.Abidi教授一個問題:“Dear Professor, which classes do you think are of the most importance for RF IC research as an undergrad?” 意思是,親愛的教授,哪門課程對學習RFIC最重要呀?
教授說:“All of them. Believe me, all of them.”答案是,每一門。
從經驗能力來說
模擬芯片的設計已經非常吃經驗了,射頻芯片在這方面有過之而無不及。
射頻IC設計與電子元器件關系緊密,設計匹配布局復雜,需要熟悉大部分的元器件特性及不同的生產制造封裝工藝。因為射頻電路可能會因附近的外部電路、電場/磁場、溫度、電磁信號和其他環境因素的干擾而經歷巨大的性能變化,對所有這些因素的建模與預測分析幾乎可以上升為玄學。
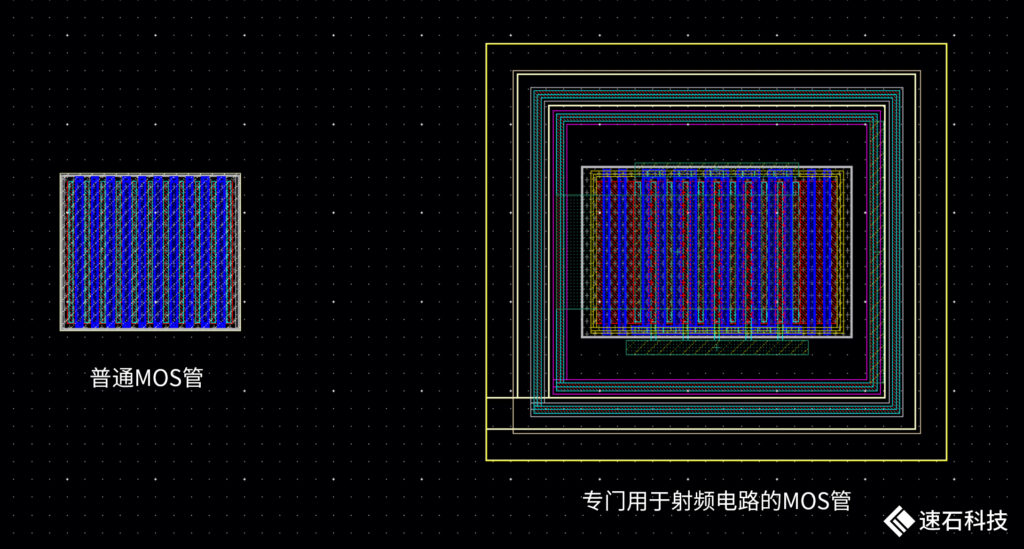
對工程師來說,不同實際應用場景下的經驗通用性不強,牽涉性能指標多,整體輔助工具少,往往需要挑戰工藝極限。整個設計過程中存在對諸多指標的權衡與取舍,有很大的不確定性,對設計者的經驗要求極高。
這也是為什么很多射頻IC設計公司都是IDM(Integrated Design and Manufacture,垂直整合制造)模式,因為需要多種不同的生產工藝,與foundry廠的生產鏈各環節緊密關聯,門檻相當高。
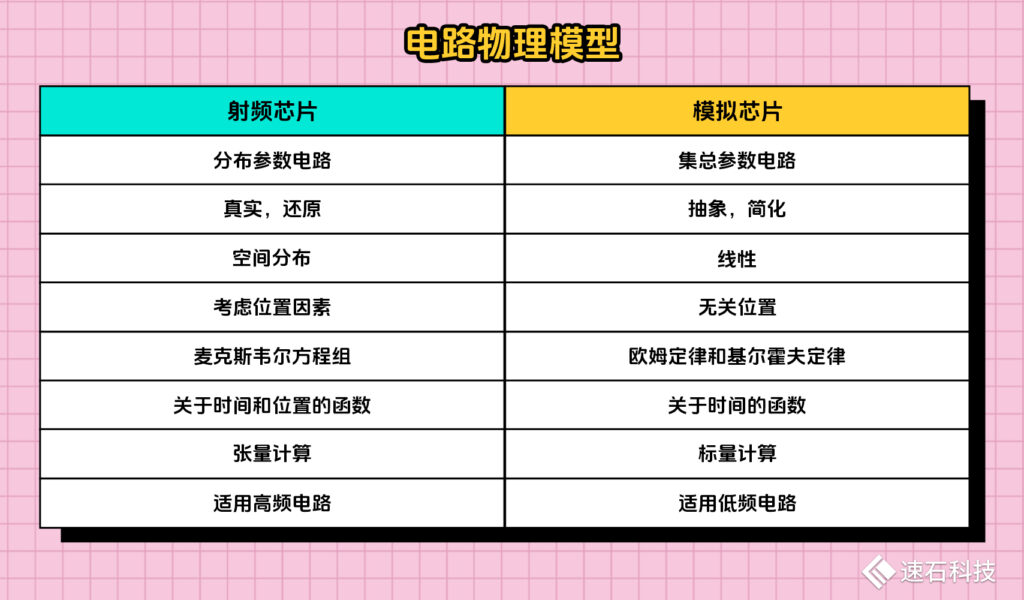
02、電路物理模型
從電路物理模型角度,射頻芯片可以說是模擬芯片的高階現實版,模擬芯片算是抽象簡化版。
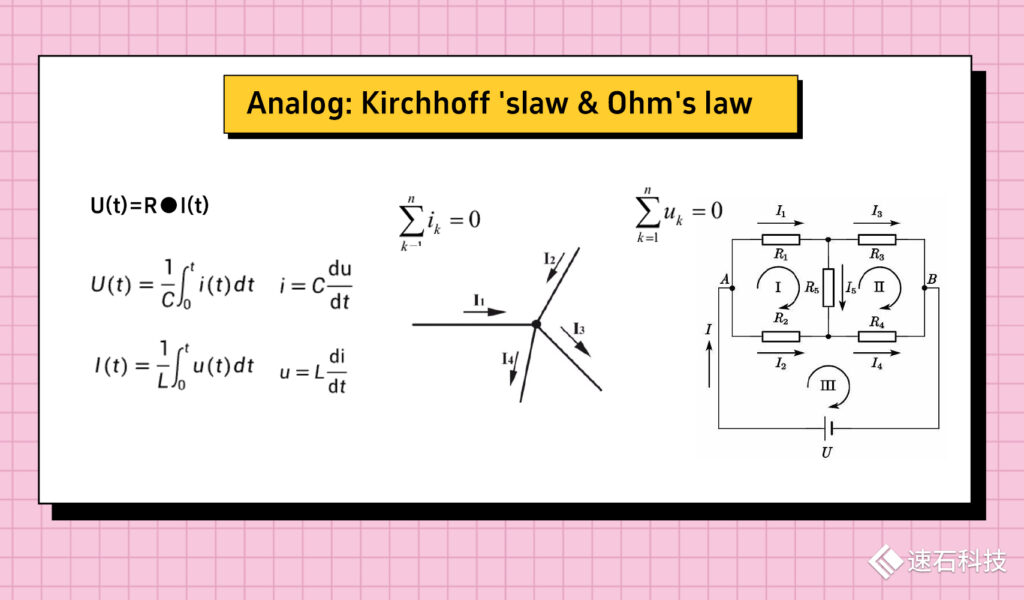
模擬芯片屬于集總參數電路,是一種常用的簡化電路模型。它將電路中的元件抽象為等效的電阻、電容和電感等參數,以簡化的形式描述了復雜電路的行為,減少了繁瑣的計算步驟。
歐姆定律和基爾霍夫定律是集總參數電路的兩個基本定律,只跟電路的連接方式有關,與元件的位置無關。
模型是關于時間的單變量函數,屬于標量計算(即只有大小,沒有方向的量)。
適用于描述低頻電路或電路中信號波長遠大于電路尺寸的情況,是麥克斯韋爾方程在低頻電路中的特解。
公式一般長這樣,看著是能讓人算出來的樣子:
射頻芯片屬于分布參數電路,它將元件建模為具有空間分布的電阻、電容和電感。
分布參數電路考慮了電路中元件在電路中的位置因素,可以更準確地描述信號傳輸過程中的相位、功率損耗等因素;也考慮了電路中各個導線和元件之間的長度影響,即電流或信號在空間上的分布變化。
對應的算法和理論基礎的是麥克斯韋爾方程組和電磁場、電動力學。
模型是關于時間與位置的多變量函數,是復變函數,屬于張量計算(可理解為一個n維數值陣列)。
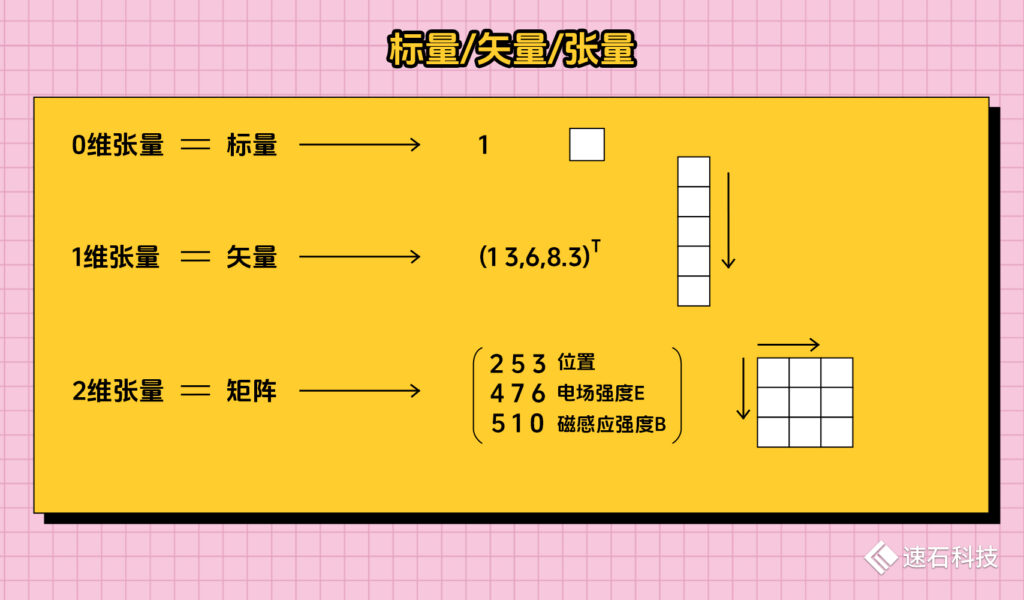
適用于描述高頻電路或電路中信號波長大于等于電路尺寸、頻率特性受傳輸線長度影響較為顯著的情況。
公式一般長這樣,人是算不出來的,要用計算機輔助:

總結一下,射頻芯片與模擬芯片在電路物理模型上的差異:
03、仿真計算特性
關于模擬芯片設計的計算特性,我們在《五部曲-模擬IC》里重點介紹了兩大常見數值計算場景:多corner和蒙特卡羅Monte Carlo,這兩種方法的單個任務之間都相互獨立,沒有數據關聯,很適合進行分布式并行計算。
但每一個任務進行的都是瞬態仿真,用于分析電路在特定時間段內電壓和電流的變化趨勢,仿真結果跟上一個時間的狀態相關,是個串行的過程。
單純求微分方程數值解,數據量相對較小,主頻敏感,計算并行受限較大。
在時域分析上,計算量大,在頻域上計算量小。
常用工具Spectre,有針對AVX512指令集優化(以并行方式對大量整數或浮點數執行算術運算)。
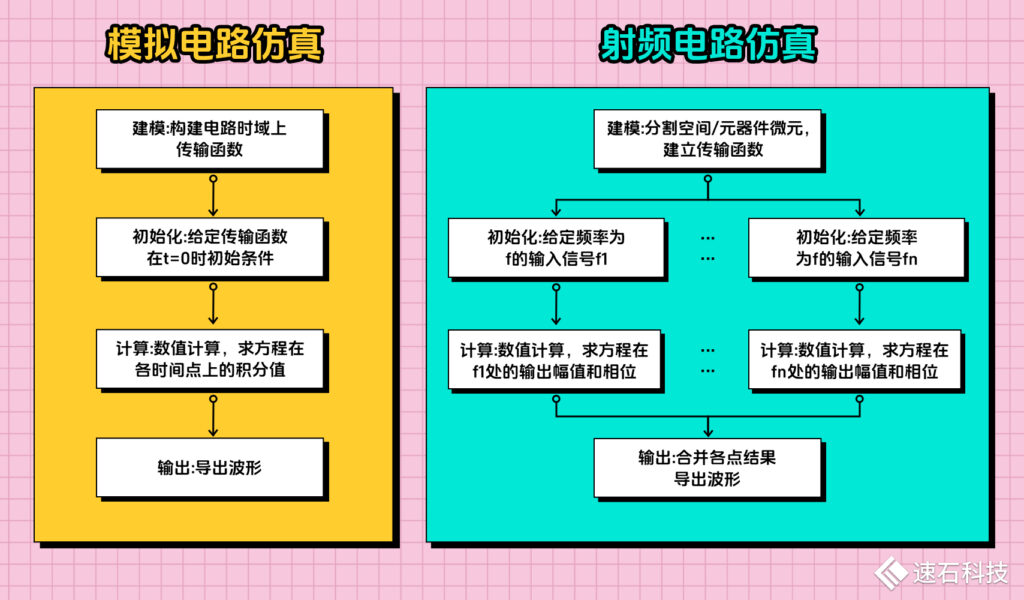
射頻芯片設計的計算特性,在模擬芯片的基礎上,還是很不相同的。
射頻電路對頻率敏感,通常在頻域中建模,在頻域和時域分析上,計算量均較大。常用FEM有限元分析法對目標電磁場空間進行切割,劃分成大量四面體,再對每個較小的區域進行計算分析。

無論是對不同頻域的取點,還是有限元法的切割,天然具備多線程與分布式優勢,適用并行計算,存在大量SIMD指令(即單指令多數據運算,其目的就在于幫助CPU實現數據并行,提高運算效率)。
張量計算,數據量大,算力需求高。
常用工具ADS,有針對AVX512指令集優化。
因為是求解空間問題,所以部分工具可用GPU。
總結一下,射頻芯片與模擬芯片在仿真計算特性上的差異:

三種電磁場仿真技術
FEM/MoM/FDTD
近些年,主要有三種電磁仿真技術:FEM有限元分析、MoM 2.5D矩量法和FDTD有限時域差分法。
原則上,他們都能解決相同的問題,但卻有各自更適合的場景。
01、FEM有限元分析
FEM(Finite Element Method)有限元分析法是真正的3D場求解器,可以分析求解任意形狀的3D結構,是最靈活的電磁仿真分析方法,也可以說是一種暴力破解算法。
這種算法將整個幾何模型劃分為大量四面體,每一個四面體都是由四個等邊三角形組成。也就是說,整個目標空間被劃分為N個較小的區域,并用局部函數表示每個子區域中的場。
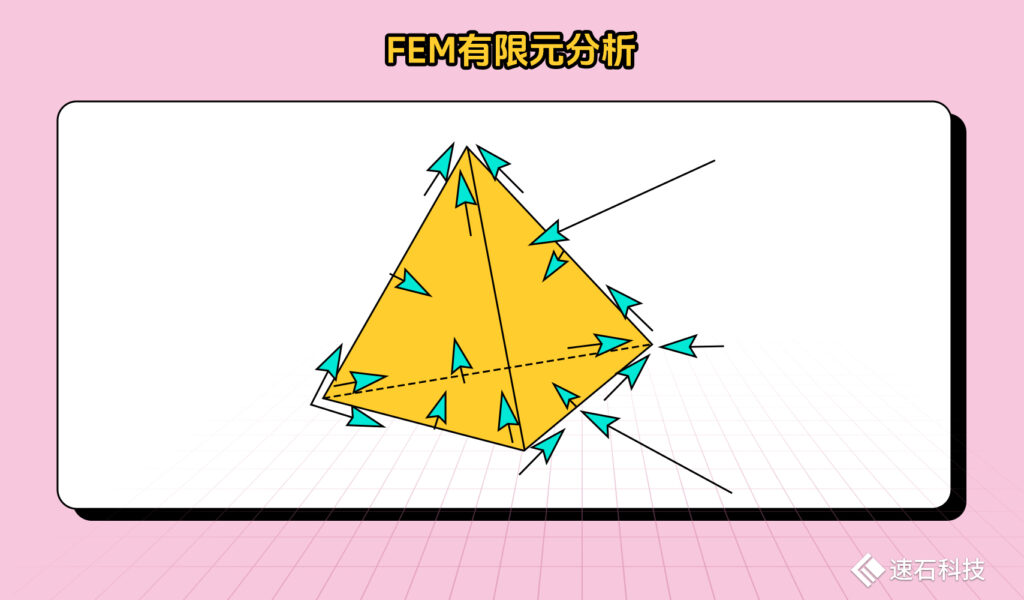
然后把一個個空間拿出來,對微分形式的Maxwell方程在頻域進行求解,其求解的未知量是每一個小網格的電場與磁場。
對于幾何復雜或電氣大型結構,網格可能會變得非常復雜,形成具有許多四面體的網格單元,導致需要求解巨大的矩陣。
所有端口激勵只需要一個矩陣求解。
通常用于復雜3D結構的求解,整體消耗仿真資源大,仿真速度慢。
02、MoM 2.5D矩量法
FEM有限元分析是一個三元方程組,計算量很大。
而MoM(Method of Moments)2.5D矩量法,是專門針對3D層狀結構出的優化算法。它根據半導體平面工藝的結構,做了一定數學上的簡化和等價,把三個未知數簡化成兩個未知數,加快了求解速度。
這種算法的關鍵在于:整個幾何模型的背景結構信息都包含在了格林函數中,同一介質上的不同結構,只需要計算一次格林函數。所以只需要對需要求解的金屬結構劃分網格,通常由矩形、三角形和四邊形網絡單元組成。
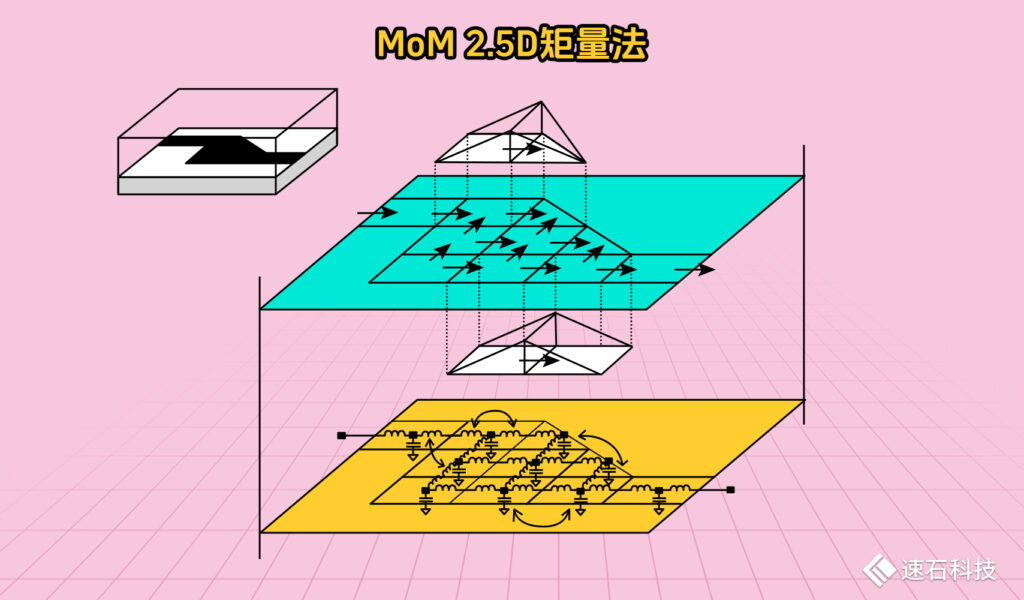
因此,“平面”MoM網格比FEM所需的等效“3D體積”網格更簡單且更小。
而網格單元數量的減少可以減少未知數并實現極其高效的模擬,這使得MoM非常適合復雜分層堆疊結構的分析。
MoM矩量法對積分形式的Maxwell方程在頻域求解,需要求解的未知量為金屬的表層電流分布。得到電流分布之后,仿真器再根據格林函數進行數值積分,即可得到求解空間任何點的場分布。
所有端口激勵只需要一個矩陣求解。
理論上,對于任意結構或者非均勻介質,矩量法也可以求解。但需要對背景環境進行額外描述,導致未知量數目上升,求解效率下降,反而不如求解微分方程的FEM有限元分析法高效。
因此,MoM矩量法不適用于一般的三維結構,主要適用求解3D層狀結構,常用于片上無源器件。
03、FDTD有限時域差分
FDTD(Finite Difference Time Domain)有限時域差分法,跟FEM一樣,也是真正的3D場求解器,可以分析任何形狀的3D結構。
FDTD通常使用六面體網格單元(也就是“Yee”單元),對微分形式的Maxwell方程在時域進行求解,當前時刻的電場磁場矢量值由結構中前一時刻的電場磁場值以及它們的變化情況直接計算得出。
相對于FEM和MoM的顯著優勢之一是FDTD技術不需要矩陣求解,對于時域上的問題,即便復雜結構的求解也僅使用少量內存,非常高效。FDTD 還非常適合并行化,這意味著可以利用GPU處理能力來加快模擬速度。
必須為幾何N端口設計上的每個端口運行一次仿真。
小結
MoM仿真速度會更快,但是FEM的應用范圍更廣更靈活。
如果待求解的結構是“平面”或者說層狀結構,可以優先使用MoM仿真,提高設計效率。比如PCB互連、片上無源器件以及互連和平面天線。當然,如果結構很簡單,采用FEM分析也差別不大。
如果考慮幾何形狀的復雜性和問題大小,FEM為大量端口問題提供了最有效的解決方案。
FDTD在時域進行求解,這意味著它對于連接器接口和轉換執行時域反射計 (TDR) 分析非常有用。
射頻_電磁場仿真工具
HFSS/ADS/EMX
電磁場模擬已經越來越成為射頻電路設計人的必備技能之一。尤其是專門為射頻和微波電路分析而開發的計算機輔助工具的使用,讓射頻芯片工程師能夠獲得前所未有的仿真能力。
當然,這并不意味著有了工具就能解決電磁仿真問題,前面已經反復說了,RFIC設計對經驗要求非常高。但通過使用更高效的電磁仿真工具,工程師可以相對低成本地驗證設計概念,或在仿真中融入更完整更真實的數據,減少外部條件限制。
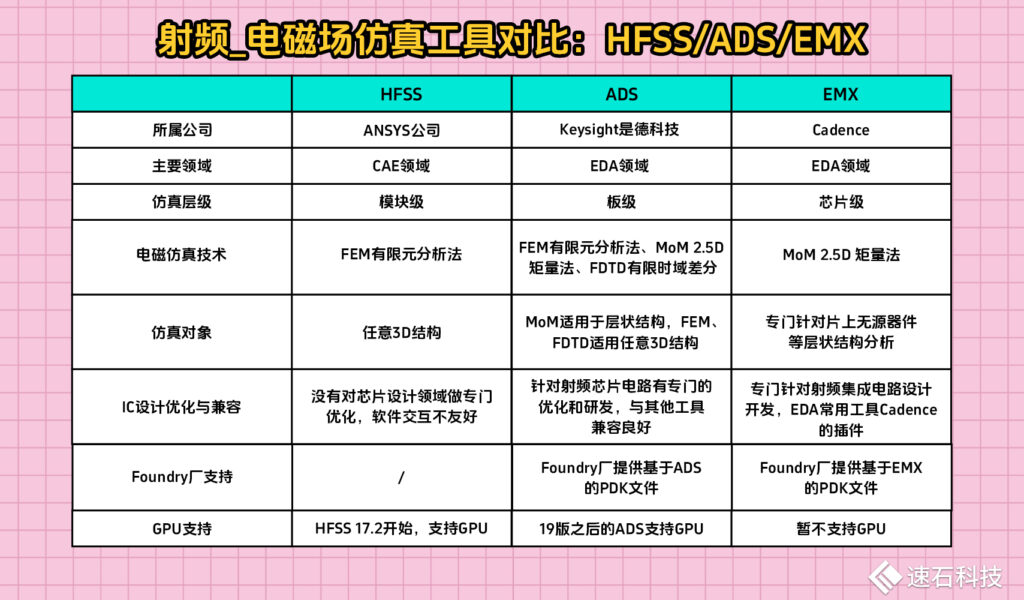
目前,業界主流仿真工具主要有HFSS/ADS/EMX。
在射頻領域,TA們有不同層級的仿真對象:EMX是芯片級,ADS是板級,HFSS是模塊級。雖然都叫電路,都是同一套物理規則出來的東西,但是制造工藝和尺寸不一樣,所以適用不同的工具。

01、HFSS
HFSS,是世界上第一款商業化的3D電磁仿真軟件,堪稱電磁場仿真業界標桿,現在屬于Ansys公司。
HFSS使用的是FEM有限元分析法,所以非常通用,適用于任意3D結構。
但通用也就意味著沒有強針對性,HFSS把一套叫做有限元分析的數學方法應用在了電磁學領域,當然,也可以應用在其他工程領域。因為沒有對芯片設計領域做專門優化,軟件交互方面不夠友好。
HFSS主要面向的是波導、傳輸線那種比較大的射頻元件和模塊設計,偏宏觀的電磁仿真。
如果要界定領域的話,HFSS比較難評,既可以放到CAE領域,也可以放到EDA領域。一般而言,在智能制造/汽車制造場景下用HFSS進行電磁場仿真更多,當然,也可以用于部分芯片設計場景。
我們寫過一篇實證,詳情可戳:超大內存機器,讓你的HFSS電磁仿真解放天性
02、ADS
ADS和EMX就不一樣了,是純粹的EDA領域工具,在處理芯片設計場景的電磁場仿真使用較為廣泛。
這類電磁場仿真工具在算法上,通過Maxwell方程組求解元件的空間電場分布,將元件映射為特定的RLC電路,做到“化場為路”。這既能降低仿真分析難度,又能將元件的有限元物理模型,轉換成對應的Spectre/HSPICE網表,供一般電路仿真工具使用。
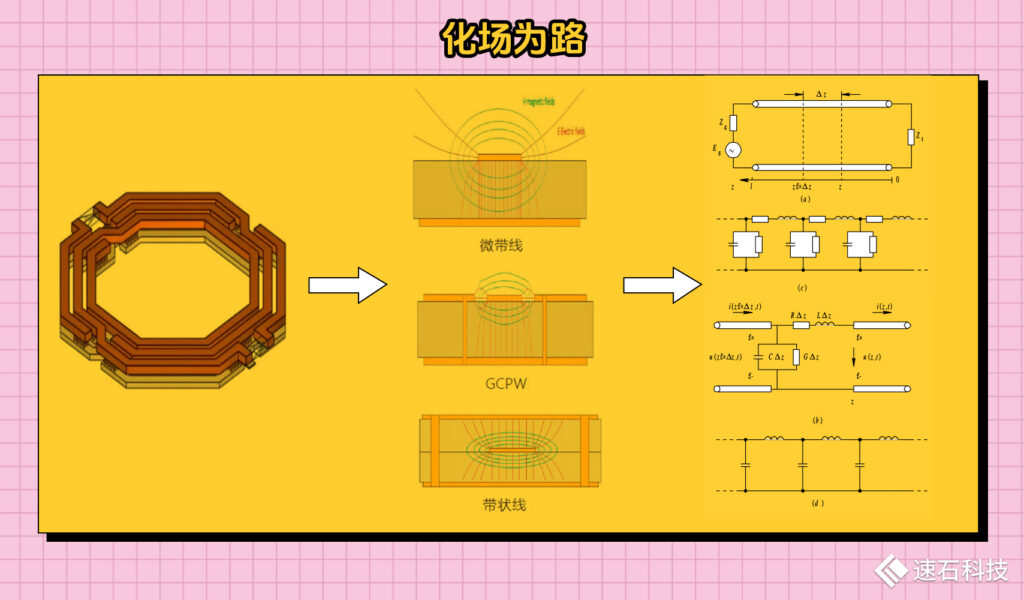
ADS,屬于Keysight是德科技,針對射頻芯片電路有專門的優化和研發,既可以做三維電磁場仿真,也可以針對PCB布局和部分集成電路設計場景。Keysight跟各大元器件廠商都有廣泛合作,可以提供最新的Design Kit供用戶使用。
ADS適合對片上的電路/元器件做分析仿真,適用小規模RF/MMIC設計,如果需要模擬一個大的模塊,HFSS可能更合適。
ADS同時支持FEM有限元分析法與MoM 2.5D矩量法,也可選FDTD有限時域差分。
MoM適用于層狀結構,而使用FEM或FDTD方法時可以適用任意3D結構。
ADS與其他工具兼容良好,免去跨平臺數據導入導出,對Virtuoso提供比HFSS更好的兼容性。
在電磁與射頻的設計中,經常需要通過HFSS設計天線,然后通過ADS來驗證電路,這個時候就需要兩者的聯合仿真,以S參數作為中繼。
而根據前面提到的,射頻電路因為高頻產生的電磁場效應,會因為外部環境因素的干擾經歷巨大的性能變化。所以,射頻芯片在設計之初就需要Foundry廠提供的相關工藝信息,因為需要知道整個芯片制作工藝里面的材料特性和工具結構才能仿真建模。
早期,ADS占據絕對主導地位,Foundry廠會提供基于ADS的PDK文件,現在逐漸也開始提供基于EMX的工藝文件。
03、EMX
EMX是專門針對射頻集成電路設計開發的,作為EDA常用工具Cadence的插件存在,能與TA無縫集成,對工程師們極為友好。
芯片級的集成電路分析,屬于微觀尺度,一般使用EMX最為合適。
EMX只支持MoM 2.5D矩量法,專門針對片上無源器件等層狀結構分析,不適用bonding wire、BGA、PGA封裝等非層狀結構,橫截面非直線金屬結構。
HFSS 17.2和19版之后的ADS支持GPU處理電磁場仿真任務,且通過并行化處理后,效率提升十分顯著;EMX作為Cadence里的插件暫不支持GPU任務。
三種射頻芯片電磁場仿真工具對比
關于我們在各種EDA應用上的表現,可以點擊以下應用名稱查看:
HSPICE │ OPC │ VCS │ Virtuoso │ Calibre │ HFSS
更多半導體用戶案例,可以戳下方查看:
青芯 │ 浙桂 │ 燧原 │ 普冉 │ Alpha Cen │ 深職大
- END -
我們有個IC設計研發平臺
IC設計全生命周期一站式覆蓋
調度器Fsched國產化替代、專業IT-CAD服務
100+行業客戶落地實踐
支持海內外多地協同研發與辦公
多層安全框架層層保障
掃碼預約專家1對1溝通~

更多EDA電子書
歡迎掃碼關注小F(ID:imfastone)獲取

你也許想了解具體的落地場景:
遠離“紙上談兵”,深職大打造國內首個EDA遠程實訓平臺
普冉半導體逐步布局自主可控,漸次提升研發效率
光電兼修的Alpha Cen,如何應對上升期的甜蜜煩惱?超大內存機器,讓你的HFSS電磁仿真解放天性
暴力堆機器之王——Calibre
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
芯片設計研發平臺:
今日上新——FCP
專有D區震撼上市,高性價比的稀缺大機型誰不愛?
從“單打獨斗”到“同舟共集”,集群如何成為項目研發、IT和老板的最佳拍檔?
國產調度器之光——Fsched到底有多能打?
最強省錢攻略——IC設計公司老板必讀
解密一顆芯片設計的全生命周期算力需求
近期重大事件:
速石科技正式發布新質生產力教學科研創新平臺,聚焦跨學科專業教學實訓與科研
速石科技攜手珠海先進集成電路研究院,正式入駐橫琴ICC
速石科技與西門子、亞馬遜云科技共同推出Simcenter 仿真云平臺,助力工業領域數字化轉型
仿真云平臺,助力工業領域數字化轉型
速石科技聯合Altair打造一體化芯片綜合研發平臺,提升企業軟硬件仿真效率
速石科技完成龍芯、海光、超云兼容互認證,拓寬信創生態版圖
速石科技入駐粵港澳大灣區算力調度平臺,參與建設數算用一體化發展新范式


《芯片設計五部曲》:模擬IC、數字IC、算法仿真、存儲芯片和總結篇(排名不分先后
芯片設計五部曲之一 | 聲光魔法師——模擬IC
芯片設計五部曲之二 | 圖靈藝術家——數字IC
上兩集我們已經分別深入了模擬IC和數字IC的設計全流程,結合EDA工具特性和原理,講述怎么利用計算機技術提高模擬與數字芯片的研發設計效率。
這一集,我們把其中的算法仿真部分拉出來展開說說。
第三集:算法仿真
算法是對芯片系統進行的整體戰略規劃,決定了芯片各個模塊功能定義及實現方式,指引著整個芯片設計的目標和方向。可謂,牽一發而動全身。
不管是模擬IC還是數字IC設計,算法仿真都是第一步。通常,會由算法工程師組成獨立的算法團隊。

CPU/GPU本應該是算法仿真的常客,但因為歷史比較悠久,發展成熟,市場幾乎被英偉達和AMD壟斷,很多IC設計公司選擇直接采購IP的方式跳過這一步。
近幾年,無線通信芯片成為了算法業務的最大甲方。因為這類芯片的信號編解碼與頻譜遷移時方式十分復雜,再加上種類繁多,各國的通信協議、標準、頻率也在不斷變化。隨著我國5G通信標準的放開,算法仿真的地位與日俱進。
另一個涉及大量算法業務的場景是AI芯片,應用場景小到手機、智能家電,大至汽車。
跟前兩篇數字和模擬IC的設計場景相比,算法仿真有著非常不一樣的表現。
所以我們單獨把ta拉出來,從本質出發,結合一家無線通信芯片公司實際業務場景,看看算法仿真有哪四大特性,以及分別從個人及團隊視角出發,看我們怎么幫算法工程師解決問題,提高研發效率。
算法仿真的本質
算法(Algorithm),是指在數學和計算機科學間,一種被定義好的、計算機可施行指示的步驟和次序。算法代表著用系統的方法描述解決問題的策略機制,解決一個問題可以有很多種算法。
舉個栗子。
求解下圖黃色區域圖形面積,我們有三種算法。

方法一:你可以直接用三角形的面積公式解。這種方法快速、直觀,小學文化程度即可,但局限性也高、不通用,不適用于圖像復雜的情況;
方法二:也可以用符號計算求不定積分。求解析解方法,適用于各類不定積分中有解析表達式的函數圖像。計算門檻較高,大多手算很少有計算工具。而且實際工程應用場景中,很多函數沒有解析解;
方法三:用數值計算方式解積分,求數值解。數值計算法適用范圍最廣,可以求任意函數曲線的定積分,將函數一段段分解,再算出面積。不同的分解方法就代表不同的算法。這種方法只能求數值解,無法求解析解且計算量巨大,適合機器計算,不適合人工計算,在工程領域應用甚廣。

在芯片設計領域,算法仿真的本質是評估不同數值計算解法的工作量、計算效率適用范圍,選出最優算法,使ta不僅要滿足算得最快、最準,而且還要能確保功能、精度、效率、吞吐量等指標。
算法仿真是一個不斷迭代、優化的過程,一般都要反復調整參數,進行N次回歸測試。
一家算法團隊的小目標
一家無線通信芯片公司算法團隊,開局情況如下:
算法部門共有15人,全公司有480核共享本地資源,各部門按需提前申請使用。
根據公司的業務發展目標,大致估算出未來新算法項目任務總數為1283980。
假設一:全公司本地資源均歸他們用,每個人的資源上限是32核;
假設二:單case運行時間為10小時;
假設三:回歸測試次數為1次;
假設四:一個case只有一個job,且只用一個核

總運行時間達到3.05年。
啊這。。
可能打開方式不對,再來:
增加假設五:人均資源上限逐漸提升到120核;
假設六:算法團隊人數逐步擴張至46人;

總運行時間約96.92天。
嗯,這回挺好。
想得是挺美,小目標怎么實現?
現實一:公司共享本地資源不可能只歸算法部門專用;
現實二:單case運行時間,難以估計;且一個case往往不止一個job,且一個job未必只用一個核;
現實三:回歸測試只有1次,幾乎不太可能,總任務數可能數倍增長;
現實四:本地機房從480核要擴張十幾倍,可不止是買買買硬件,機房建設、運維人力、硬件維保、存儲網絡、環境部署等等,都不是小事;
現實五:算法工程師要求非常高,招聘難度極大。
真是,沒一個字讓人愛聽的。

如果是日常模擬/數字芯片設計,想做算力規劃,咱們還是有思路的,可以看看這篇:解密一顆芯片設計的全生命周期算力需求
但算法仿真這里,此路不通。
我們先看看算法仿真的特性:
算法仿真的四大特性
下圖是這家無線通信芯片公司算法團隊9個月實際日平均資源用量波動總覽圖:

01 需求不可測
從個人角度出發,算法團隊每個人的算法任務都是互相獨立,互不影響的。算法確定之后,每一輪的計算量基本確定(但case分解成的job數,job占用的核數基本確定),每個算法任務的單次耗時與回歸測試次數都是不一樣的,這導致最后的資源需求完全不可測。
如果再疊加團隊使用因素,資源的不可測性也會被成倍地放大。如果原先個人的資源使用區間是0到250核小時;如果團隊內有20人,那不可測區間就放大至0至5000核小時。
02 短時間使用量波動巨大
除了算法任務需求的不可測性,資源使用量的波動還受實際算法任務的進度影響。
每個算法工程師的工作獨立且進度不一,有時可能大量任務同時批量運行,也可能部分在調試,部分在運行,甚至可能一個在運行的任務都沒有。
不同工程師的工作進度差異與所用算法不一,不僅導致了波峰、波谷間的資源使用量差距極大,而且這樣的波動可能發生在極短時間內。
極限情況:所有工程師都在頂格跑任務,5520核的資源量瞬間拉滿(100%);而下一刻只有10%的工程師在跑任務,且每人都只使用自己配額80%的資源量,那總資源僅使用了一部分。
不同公司的算法團隊之間,因為團隊規模與業務差異,資源用量差異也非常大。
03 資源需求類型多樣
算法仿真整體來說,對資源的各方面需求并不算高。
但不同算法的需求都不一樣:
有的需要單核4G內存的機型,有的要單核8G內存的機型;
有的算法對存儲要求高,有的算法對存儲沒要求:
有的涉及圖形計算,甚至還需要用到GPU機型。
04 長期可持續狀態
上述三大特性,都不是突發現象,屬于算法團隊的日常工作狀態。
這一狀態的長期可持續性,我們需要對此做好足夠的準備。
一種動態思路:增加時間維度
算法仿真的四大特性決定了:按這家公司原來的靜態處理方式,也就是把任務量當成恒定的,通過加人加機器的方式來滿足研發需求,變得很不現實。哪怕頂格準備資源,資源利用率也會長期處于較低狀態。
那按動態處理方式,也就是隨著時間變化,靈活根據需求匹配不同規模/類型資源的方式來動態滿足研發需求,從個人及團隊視角出發,看我們怎么幫算法工程師解決問題,提高研發效率。
01 算法工程師視角
1)資源無需申請,即開即用再也不用跟同事搶資源或者漫長的排隊等待了,也不用走繁瑣的資源申請流程。
2)資源選擇空間變大選擇空間變大,資源類型變多,可用資源上限變高,可以靈活選擇更加適配算法任務的資源類型。
給大家打個樣:5000核大規模OPC上云,效率提升53倍
3)提交任務立馬就能跑,告別等待
提交任務立馬就能跑,一整套研發環境現成的,即開即用。
靈活切換,今天跑一百,明天跑一萬,無需等待環境配置。
4)以前怎么用,現在就怎么用跟本地相比無感知,對用戶使用習慣沒有任何門檻,不需要調整任何腳本。
5)任務跑得快,效率線性增長
多case高并發執行。同一批算法任務之間互相獨立,可以做到效率線性提升。
02 團隊管理視角
1)動態方式解決資源不可測問題
算法任務的不可預測且波動巨大,導致了資源預測與規劃基本不可能。
按傳統靜態處理方式來解決問題:
按頂格規劃,這筆賬都不用算,會造成黃色區域的巨大浪費;
按中間取值準備,當某個時間點算法仿真短時間內任務量激增,就會出現人機不匹配,不是有人力沒機器,就是有機器沒人力。這種錯配導致資源利用率極低,影響研發進度。

圖中3-5月,峰值算力就從200核攀升27倍達到5520核,隨即又迅速從5520核下跌到500核左右,這波動幅度簡直比過山車還劇烈。而且毫無規律。
我們的動態處理方式,會隨著時間變化,靈活根據當前時間點任務需求匹配不同規模/類型資源的方式,動態滿足研發需求。
不管500核還是5000核,我們都能實時根據需要,滿足整個團隊的大幅波動資源需求,保障日常算力和峰值算力任務調度效率。
2)Auto-Scale自動伸縮,隨用隨關不浪費
Fsched調度器的Auto-Scale功能,能解決團隊資源利用率與成本問題。資源“自由”的同時不浪費。
一方面隨用戶任務需求,設置自動伸縮上下限,自動化調用資源完成任務;
Auto-Scale功能可以根據任務運算情況動態開啟云端資源,需要多少開多少,并在任務完成后自動關閉,讓資源的使用緊隨著用戶的需求自動擴張及縮小,最大程度匹配任務需求。

這既節約了用戶成本,不需要時刻保持開機,也最大限度保證了任務最大效率運行。中間也不需要用戶干預,手動操作。
另一方面我們還能監控用戶提交的任務數量和資源需求,在團隊內部進行資源及時適配,解決錯配問題。
想了解更多關于Auto-Scale的內容,點擊:EDA云實證Vol.10:Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
3)提升團隊整體運營效率
我們的運營數據dashboard能讓團隊管理者監控各個重要指標變化,從全局角度掌握項目的整體任務及資源情況,為未來項目合理規劃、集群生命周期管理、成本優化提供支持。
還能根據不同成員或小組的業務緊迫程度和業務重要性,合理分配與控制用戶使用資源。
4)全球數據中心解決資源的瓶頸
我們的全球數據中心,能持續穩定地提供用戶所需資源類型及數量,分鐘級調度開啟上萬核計算資源,滿足業務緊迫度。
用戶可以選擇自主選擇大內存、高主頻等多樣化的資源類型來滿足不同算法需求。一旦發現所選資源類型與算法任務不匹配,還可隨時中止任務、更換資源類型,任務進度不受影響。

附加題環節:對研發來說,能不能清晰看到任務的運行狀態?實時監測進度?任務異常時能不能自動告警?對IT來說,資源用量如何?怎么判斷用戶資源使用量是否符合分配模式?系統負載過高是否有直接的告警?我們會單獨開一篇,聊聊什么叫基于業務的監控與告警。
芯片設計五部曲的第三集——算法仿真篇到此結束啦。一起期待下一集吧~
關于fastone云平臺在各種EDA應用上的表現,可以點擊以下應用名稱查看:
- END -
我們有個IC設計研發云平臺
集成多種EDA應用,大量任務多節點并行
應對短時間爆發性需求,連網即用
跑任務快,原來幾個月甚至幾年,現在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多EDA電子書
歡迎掃碼關注小F(ID:iamfastone)獲取

你也許想了解具體的落地場景:
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化,3.5小時完成20萬分子對接
這樣跑COMSOL,是不是就可以發Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
5000核大規模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關于為應用定義的云平臺:
芯片設計五部曲之二 | 圖靈藝術家——數字IC
芯片設計五部曲之一 | 聲光魔法師——模擬IC
【案例】速石X騰訊云X燧原:芯片設計“存算分離”混合云實踐
【ICCAD2022】首次公開亮相!國產調度器Fsched,半導體生態1.0,上百家行業用戶最佳實踐
解密一顆芯片設計的全生命周期算力需求
居家辦公=停工?nonono,移動式EDA芯片設計,帶你效率起飛
缺人!缺錢!趕時間!初創IC設計公司如何“絕地求生”?
續集來了:上回那個“吃雞”成功的IC人后來發生了什么?
一次搞懂速石科技三大產品:FCC、FCC-E、FCP
速石科技成三星Foundry國內首家SAFE云合作伙伴
EDA云平臺49問
億萬打工人的夢:16萬個CPU隨你用
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費4小時5500美元,速石科技躋身全球超算TOP500

《芯片設計五部曲》:模擬IC、數字IC、存儲芯片、算法仿真和總結篇(排名不分先后
上一集我們已經說了,模擬IC,更像是一種魔法。
我們深度解釋了這種魔法的本質,以及如何在模擬芯片設計的不同階段,根據常見的EDA工具特性和原理,從計算角度幫助模擬工程師更高效地完成吟唱施法。
第二集:數字IC
假如我們想要錄制一段聲音,模擬信號的做法是把所有的聲音信息用一段連續變化的電磁波或電壓信號原原本本地記錄下來。而按照一定的規則將其轉換為一串二進制數0和1,然后用兩種狀態的信號來表示它們,這叫數字信號。
處理數字信號的芯片就是數字芯片,比如常見的CPU、GPU。

當聲音變大或變小了,模擬信號都會跟著變化,所以模擬信號有無數種狀態。狀態之間微妙的差異,需要人的經驗判斷,有點玄學的成分。
而數字信號永遠只有0和1兩種狀態,信號的轉換嚴格遵循邏輯關系,一個輸出對應唯一確定的結果,程序完全依照輸出指令執行,這是科學。
數字IC設計工程師的設計目標:在PPA(Power、Performance、Area)三個指標上追求完美的平衡。
怎么玩轉這門科學?
這,是一種藝術。
今天,我們就從資源需求、并行特征、數據敏感度等角度展開聊聊在數字芯片設計各階段,如何利用不同EDA工具的特點,讓數字芯片的設計研發效率獲得顯著提升。
和模擬芯片相呼應,這篇還是從計算角度出發,至于調度/管理/數據/協同/CAD等視角,會在后面的文章里體現~(比如第三集
和模擬相比,數字芯片需要使用EDA工具的場景更多,IC工程師們對于計算機的使用天然比較親近。但就跟《解密一顆芯片設計的全生命周期算力需求》一樣,只負責某項工作的研發可能不關心,或者只了解自己的這部分,IT對業務所知有限,也不一定清楚。除非有大佬坐鎮,大多數公司的日常大概是以拍腦袋經驗論為主。
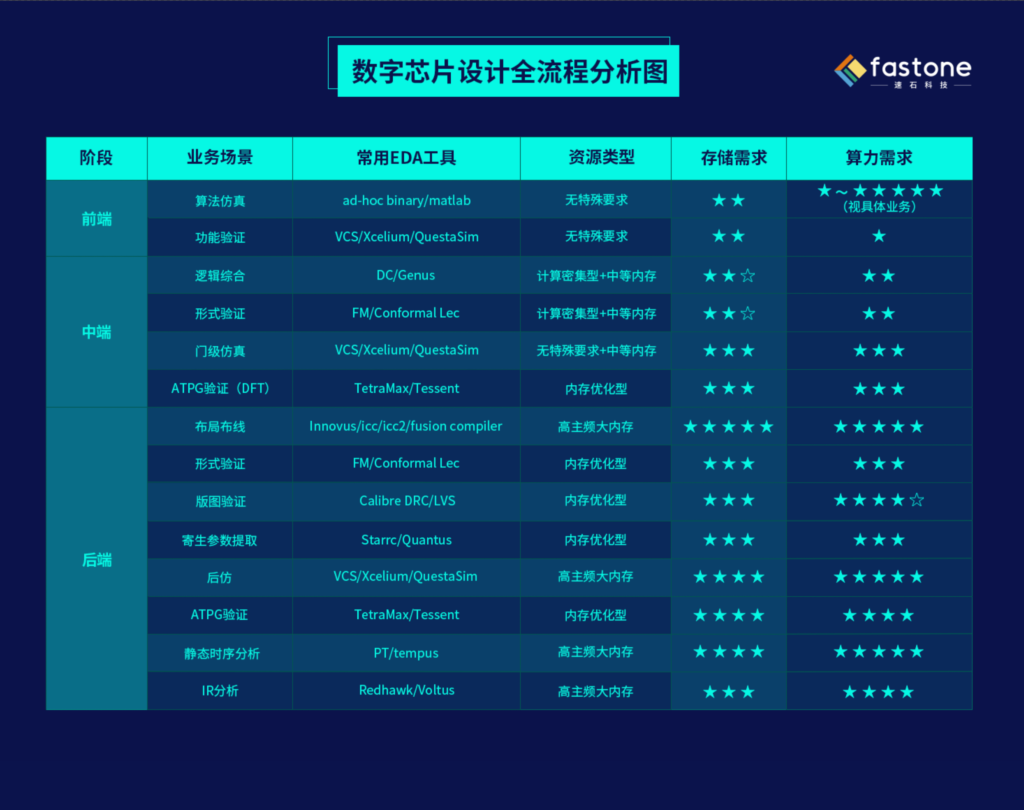
我們先來看一下大畫面,數字芯片設計全流程分析圖:
01 數字前端:前端設計/驗證
這一階段包含了規格制定、架構設計、RTL編碼等步驟。
數字前端算法仿真和功能驗證場景有大量中小任務并行,這一階段,對于資源類型和用量通常無特殊需求。
不過需注意若大量使用現有IP通常沒有算法仿真這一步。而且每家公司業務不同,算法仿真需求量差異非常大(下一集主角就是ta)。
02 數字中端:邏輯綜合與DFT實現
這一階段可分為邏輯綜合、形式驗證、門級仿真、ATPG驗證等業務場景。
數字中端呈現單、多任務混合的特點,因為計算的輸入數據中包含門延遲信息,輸入數據變多,對內存的需求相比前端有一定增長。ATPG驗證建議內存優化型,其他三種場景更加偏計算密集型。
03 數字后端:物理實現
這一階段包括布局布線、形式驗證、版圖驗證、寄生參數提取、后仿、ATPG驗證、靜態時序分析和IR分析等業務場景。
數字后端基本都是多任務,由于包含版圖的寄生參數,信息量非常大,普遍需要大內存機器。其中,布局布線、后仿、靜態時序分析、IR分析的大任務數量非常多,對主頻也有要求,需要兼具高主頻和大內存的資源。
資源需求
后端>中端>前端,數字后端·真·資源黑洞
把數字IC設計前、中、后端三大階段進行資源需求對比。

可以看到無論是任務運算時間、所需計算資源、存儲需求還是IP與輸入數據量級上,數字前中后端形成了非常明顯的階梯結構,整體資源需求呈現前端<中端<后端的趨勢。
這是由三個階段的具體工作內容決定的:
數字前端,用RTL代碼將芯片架構師的設計寫出來,前端驗證也主要是針對RTL的功能進行驗證,偏邏輯功能。
數字中端,需要將RTL代碼綜合成網表并規劃、插入各種用于芯片測試的邏輯電路,需要加入Foundry廠提供的標準單元庫的工藝參數,驗證也到了邏輯門這一級。
數字后端負責芯片的物理實現,先將電路網表通過自動布局布線畫成版圖,再進行寄生參數提取,創建一個可以精確模擬數字電路響應的模型,這一階段會加入版圖的寄生參數。
從代碼到邏輯門電路再到物理層,隨著階段的演進,信息量逐級遞增,計算時所需消耗的資源量也隨之增加。
而在28nm以及更先進制程下,包含的工藝參數更多,電路更復雜,前中后端每一階段的信息量級還會被進一步放大。

哪怕前端RTL基本一致,中端和后端因為Foundry廠工藝參數更多更復雜,同樣的代碼計算量也是更大的。
換個思路,我們舉個栗子。
通過一個在數字前中后端都會出場的EDA工具來看看三大階段的資源需求。
VCS的主要作用是將Verilog HDL(一種硬件描述語言)轉成C語言,編譯出來并執行。作為一個翻譯官,ta的工作量取決于雙方對話的頻率,以及需要翻譯的文本量。
VCS在前端的功能驗證、中端的門級仿真、后端仿真中都有出場,在不同階段對任務資源的需求完全不同:

從前端到中端再到后端,雖然VCS的工作性質沒變,但整體來說,消耗的資源越來越多了。
綜上,數字后端設計與驗證環節相比中端和前端資源需求更高、運算時間更長、數據量更大,往往會占據整個項目周期資源需求量的50%以上。
這也就意味著,數字后端對IC設計公司的壓力相當大,能否在這一階段獲取充足的資源,是提升研發效率、保障項目進度的關鍵。
典型并行場景
靜態時序驗證&版圖驗證
并行度是我們評估任務能否通過分布式計算完成,提升效率的標準之一。
這里涉及到兩個重要的判斷標準:可拆分,互不干擾。
可拆分指的是,大任務可以分解為小任務,原任務目標不變。
互不干擾指的是,拆分為小任務之后,任務之間互相不干擾,可以不同步。
從前端到中端再到后端,任務數量越來越多。
任務的并行度決定了速度提升的空間。
靜態時序驗證:最常見且并行度較高
靜態時序驗證是最常見的設計場景之一,基本原理是檢查各信號通路上經過的門電路,然后累加門延遲,求取整個路徑的信號延遲。
沿信號通路求Delay Time的過程,就是沿信號通路不停做簡單加法。
在靜態時序驗證過程中,有一個PVT的概念。
我們需要驗證邏輯門在不同的工藝(Process)、電壓(Voltage)、溫度(Temperature)條件下的延遲。
首先,列出可能的條件,如:
工藝:TT、FF、SS……
電壓:0.9V、1.0V、1.1V……
溫度:-40°C、0°C、25°C……
隨后,窮舉每一種可能性,如:
PVT1=TT、0.9V、-40°C
PVT2=TT、1.0V、25°C
PVT3=TT、1.0V、0°C
……
最后,驗證邏輯門在每一種PVT條件下的延遲:

數字芯片中有著無數這樣的邏輯門,每一個PVT下,邏輯門都有對應的Delay Time,而P、V、T之間可以有很多種組合,就會有很多個Delay Time的情況需要驗證。
這一場景,天然適合暴力堆機器。
版圖驗證:最高并行度
模擬芯片和數字芯片,這一場景的原理一模一樣,使用的EDA工具也完全相同。
版圖驗證屬于檢查類任務,以模塊為單位,本質上是數據對比工作,重內存需求,子任務間沒有數據關聯,是數字芯片設計與驗證中并行度最高的場景。
這一階段很適合利用云上的內存優化型資源,使用“小F影分身術”(版圖分割術),通過暴力堆資源的方式快速完成任務。

關于版圖驗證,我們在《芯片設計五部曲之一 | 聲光魔法師——模擬IC》中有更詳細的說明。
數據敏感度
前端>中端>后端,但是不用擔心
我們按照數據敏感度從高到低的順序給各類設計數據排了個序:
RTL數據 > IP、PDK和版圖 > Netlist、Session、過程波形、歸檔數據和Report
好了,接下來我們看看這些數據都會出現在哪些階段:

數字前端有大量RTL代碼,甚至部分公司在此過程中還自己開發了IP,屬于數據安全等級最高的那一撥。許多公司都會嚴格管理這部分數據,設置一定的保密等級,甚至固定放在某幾臺機器上。
中端則涉及到部分的RTL代碼、IP和PDK數據,以及一些Netlist、Session和Report。
后端徹底告別了代碼,以IP、PDK、版圖和數據敏感度較低的數據為主。
如果你要做一款游戲,前端相當于游戲的源代碼,中端是詳細的角色形象設計稿,后端就是玩家拿到手的游戲光碟了。

前端泄密,恭喜你的對手達成“代碼級抄襲”;
中端泄密,別人能照著樣子把仿品做出來,但沒有源代碼參考,知其然不知其所以然;
后端泄密,等對方逆向明白,大半年時間也過去了,你的下一代產品已經在路上了。
值得一提的是,如果使用的是先進工藝,Foundry廠也會對IP/PDK數據有保密要求。
所以在選擇云上業務場景的時候,我們一般優先推薦數字后端先來。當然,會根據每家公司的實際情況進行具體分析。(以后會寫到,這次一定
那么,前端或者中端是不是就適合用云了呢?
甚至,在某些情況下,IC設計公司會面臨全部數據無論敏感度高低必須存放在本地的情況,比如一些高保密項目(軍工項目或國家重點項目),或者有點微妙的競爭關系,怎么辦?
我們有針對性的存算分離解決方案,歡迎來對號入座。
存算分離究竟是什么意思?我們又是如何實現的?掃描文末二維碼關注小F,對暗號“存算分離”搶先了解哦~
關于數字IC設計,從不同設計階段的計算任務視角出發,我們總結了四點:

芯片設計五部曲的第二集——數字IC篇到此結束啦。
敬請期待第三集!
關于fastone云平臺在各種EDA應用上的表現,可以點擊以下應用名稱查看:
- END -
我們有個IC設計研發云平臺
集成多種EDA應用,大量任務多節點并行
應對短時間爆發性需求,連網即用
跑任務快,原來幾個月甚至幾年,現在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多EDA電子書
歡迎掃碼關注小F(ID:iamfastone)獲取

你也許想了解具體的落地場景:
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化,3.5小時完成20萬分子對接
這樣跑COMSOL,是不是就可以發Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
5000核大規模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關于為應用定義的云平臺:
芯片設計五部曲之一 | 聲光魔法師——模擬IC
【ICCAD2022】首次公開亮相!國產調度器Fsched,半導體生態1.0,上百家行業用戶最佳實踐
解密一顆芯片設計的全生命周期算力需求
居家辦公=停工?nonono,移動式EDA芯片設計,帶你效率起飛
缺人!缺錢!趕時間!初創IC設計公司如何“絕地求生”?
續集來了:上回那個“吃雞”成功的IC人后來發生了什么?
一次搞懂速石科技三大產品:FCC、FCC-E、FCP
速石科技成三星Foundry國內首家SAFE云合作伙伴
EDA云平臺49問
億萬打工人的夢:16萬個CPU隨你用
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費4小時5500美元,速石科技躋身全球超算TOP500
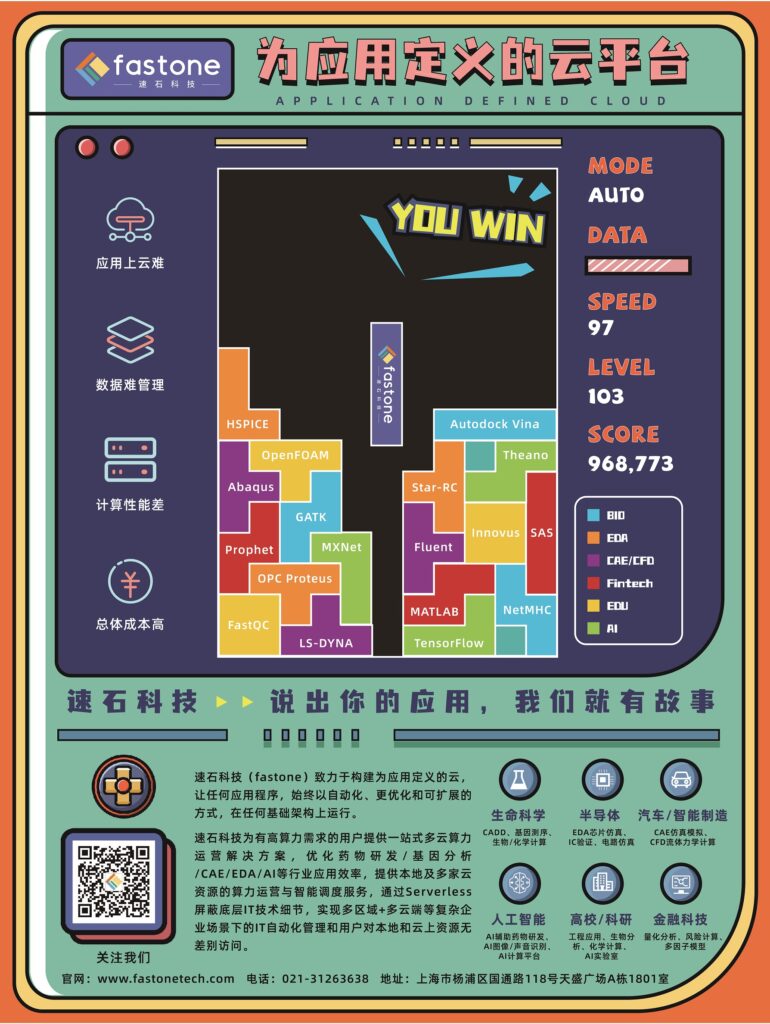

2023年開篇——芯片設計五部曲來了!
本季將會包括:模擬IC、數字IC、存儲芯片、算法仿真和總結篇(排名不分先后
第一集:模擬IC
模擬IC是負責生產、放大和處理各類模擬信號的電路,工程師通過模擬電路把模擬信號放大縮小后,再全部記錄下來,是連續的信號;而數字IC則是通過0和1兩個代號來處理手機信號、寬帶信號和數碼信號等,是離散的信號。
如果說數字IC像科學,那么模擬IC,就更像是一種魔法。
利用計算機來輔助模擬芯片設計,本質是在解一道又一道高階微分方程題。
EDA工具就是干這個的,ta的價值,就不需要我們來解釋了。
而我們今天的主題是:模擬IC設計不同階段有哪些典型的業務特點,使用的EDA工具有哪些特性,我們如何利用計算機技術提升不同業務場景的計算效率,協助模擬芯片工程師更高效地完成芯片研發工作,提升整體效率。
本篇主要從EDA工具的計算任務視角出發。
而在計算角度之外,調度/管理/數據/協同/CAD等視角,那就是另外的(價錢)篇章了~
先給大家一個模擬芯片設計全流程分析圖:
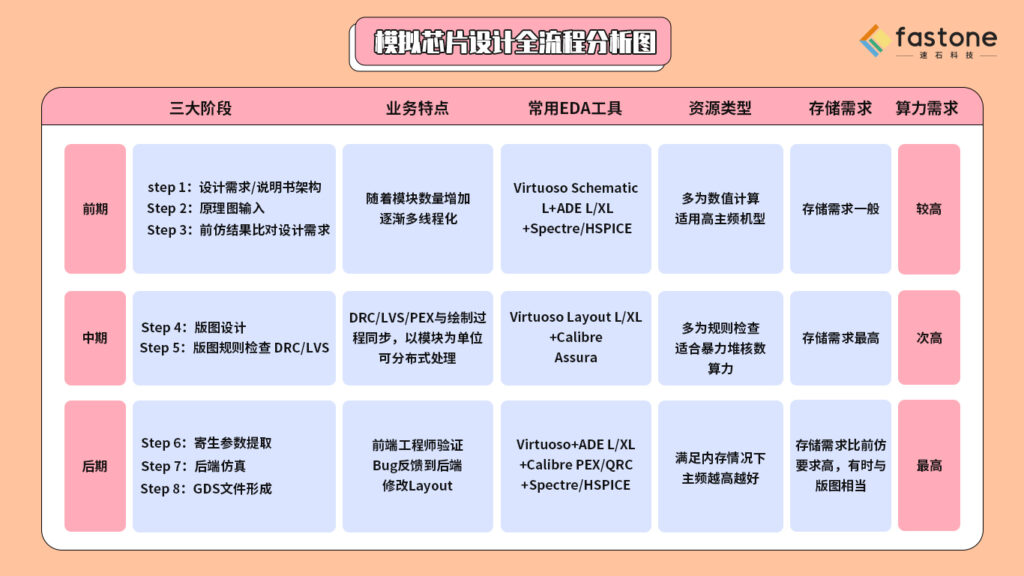
1、前仿階段:前端電路設計與仿真
本階段包括了設計需求/說明書架構、原理圖輸入、前仿結果比對設計需求3大步驟。
前仿階段本質上是數值計算,因此對主頻要求很高,一旦資源無法滿足,會直接造成CPU過載,且任務之間獨立可切割,十分適合并行。基于設計圖的設計與仿真,參數范圍較少,對內存要求不高。此階段多為多corner與蒙特卡羅Monte Carlo任務,峰值算力需求較高,存儲需求一般。
2、中期:版圖設計驗證
本階段包括版圖設計、版圖規則檢查DRC/LVS兩個步驟。版圖繪制/驗證同屬規則檢查,因為不涉及數值計算,對主頻要求不高,重內存需求。版圖可以模塊為單位進行切割,子任務間幾乎無數據關聯、適合并行。但版圖檢查量十分大,算力需求比前仿高,推薦使用多核+大內存機型,存儲要求最高。
3、后仿階段:后端仿真
后仿包括寄生參數提取、后端仿真、GDS文件形成。后仿和前仿類似,多個任務可進行分布式處理。但后仿階段任務,因為有可能涉及電磁場仿真,本質雖為數值計算,但需在優先滿足內存情況下,再滿足高主頻需求,因為加入了各類元器件的寄生參數,算力需求是三大階段里最高的,存儲比前仿要求高,有時會與版圖階段相當。
以下,我們選了三種典型場景,展開說說:
兩大超常見數值計算場景
多corner又稱為多工藝角,和蒙特卡羅Monte Carlo屬于兩種不同的電路性能與工藝誤差的估計方法,但本質上都是數值計算,前仿和后仿都會大量使用這兩種方法進行任務處理。這兩種方法里的單個任務間都獨立、沒有數據關聯,不論是多corner 還是Monte Carlo都很適合進行分布式并行計算。
推薦閱讀:揭秘20000個VCS任務背后的“搬桌子”系列故事
這個故事拆開揉碎地解釋了我們怎么幫助用戶從單機單任務單線程運行的階段大幅度跨越到了大規模任務自動化集群化運行階段,應該能很好地幫助你理解為啥分布式并行計算會大大提高計算效率。
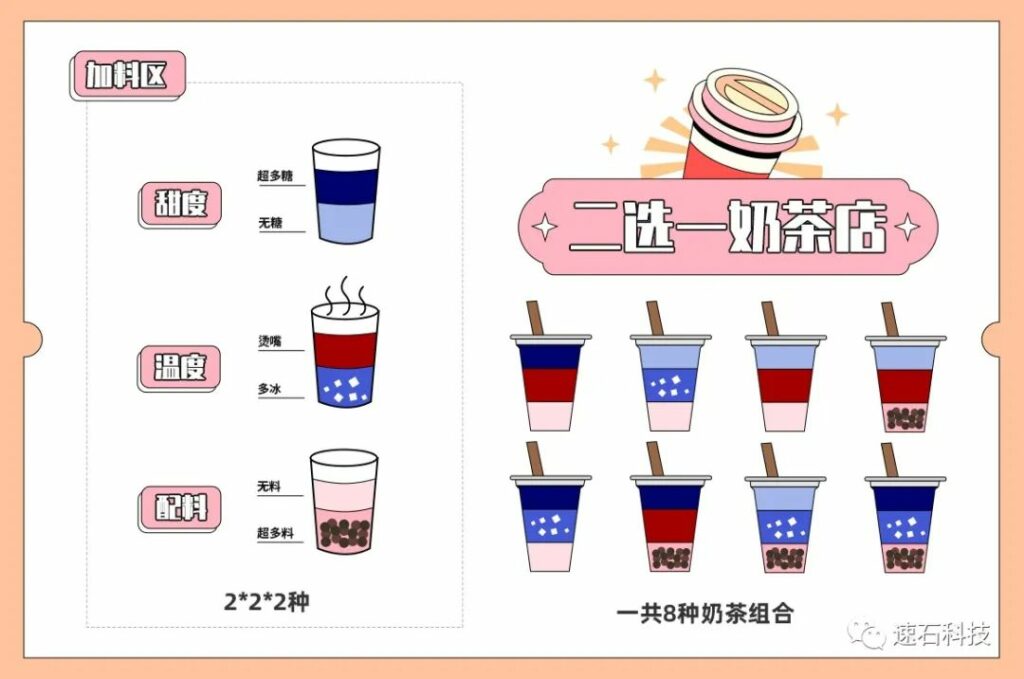
多corner是將元件的電阻、溫度、電壓等參數的誤差上下限固定后,取每個參數的極值(誤差上限或誤差下限)進行排列組合,每一個組合都是一個獨立的任務
一種組合就是一個corner,全部的排列組合即多corner。
這就像你來到一家二選一奶茶店。這家店奶茶店的甜度、熱度、加多少配料都只提供兩個選擇,你要么選擇不甜,要么最甜。你每喝一次無非都在這些選項里排列組合(2*2*2種),比如超多糖、燙嘴、超多料;下次你換一種排列組合,無糖,多冰,無料;所有選項的排列組合全點了,那就是多corner。
蒙特卡羅Monte Carlo則是在上、下限之間無窮盡地取值進行排列組合。
這次你來到了一家新的奶茶店,名字叫無窮∞奶茶店,選項完全定制化。你可以在選擇任意一個值,比如第一次你喝的是3分甜、少少冰、不加料;下一次覺得不夠甜,不冰,你點了6.6分甜、7.8分冰、加兩顆珍珠。
這樣就會有出現無數種排列組合的奶茶,這就是蒙特卡羅Monte Carlo了。
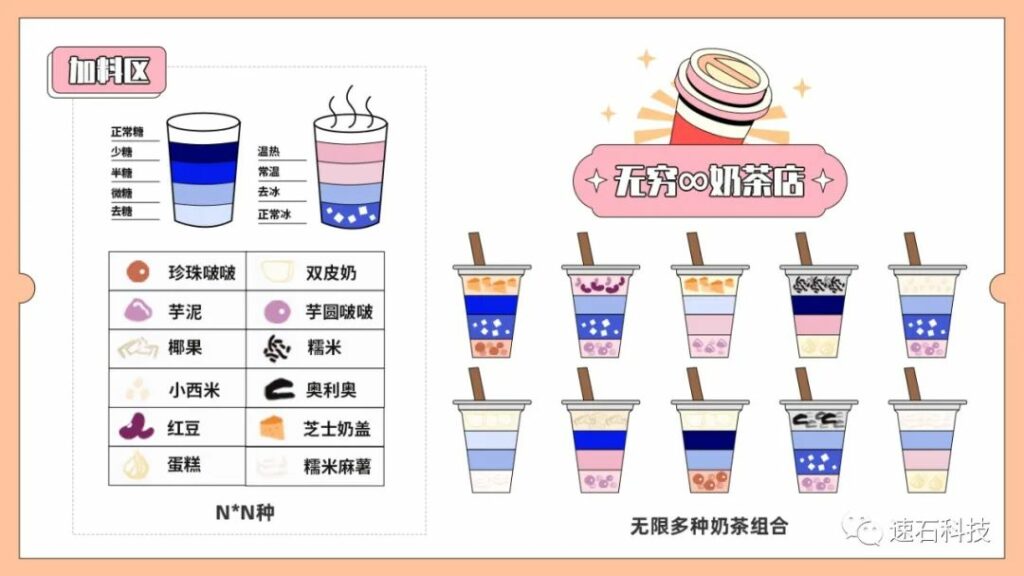
可取無數個組合的蒙特卡羅Monte Carlo可以用來估算良率的范圍,隨著取值組合越多,對工藝偏差導致的誤差估計范圍越準確,對實際的成品良率預測范圍越準確,當然計算量也會成倍提高。
不管是哪家奶茶店,這杯奶茶與那杯奶茶之間互相獨立,你喝你的,我喝我的。
這就是多corner和蒙特卡羅Monte Carlo任務特別適合分布式并行計算的本質原因。
不同任務,你算你的,我算我的,分開算,人多力量大。
不論是前仿還是后仿階段,都需要大量多corner與蒙特卡羅Monte Carlo仿真。
兩者相比,蒙特卡羅Monte Carlo仿真因為取值選擇多,組合多,計算量明顯比多corner大。
而前仿和后仿之間,后仿因涉及更多的物理參數,兩種算法的計算量都會呈幾何倍增長,算力需求也更大。
整體來說,這兩種數值計算方法任務間獨立,算力需求大,是我們幫用戶提高效率的典型場景之一。
“大家來找茬”之版圖驗證任務
版圖設計,就是把設計好的電路原理圖變成包含實際布局布線規劃內容的掩模版圖,設計師每天在電路圖上畫花花綠綠的MOS管,確定要用多少元件、用哪種排列方法,在保證芯片電氣性能的前提下,怎么跨層使得芯片體積最小、最省錢。
版圖驗證就是把畫好的版圖和原理圖進行比對,確保兩者的拓撲連接關系一致,同時檢查版圖是否符合foundry的設計工藝。
版圖設計與驗證,就像是在玩一個“大家來找茬”的游戲,首先幾個版圖設計師先一起把這張圖分工合作給畫出來。到了版圖驗證階段,就開始正式玩找茬游戲了。目的是檢查版圖有哪些地方不對,有問題的話,打回去重新畫。畫完再繼續檢查,循環往復。
如果使用“小F影分身術”(版圖分割術),可以把小F分為9個影子,每個影子只需負責找茬九分之一個版圖,影分身的數量越多(版圖切割的任務數)越多,分配的資源數越多,單位效率越高(當然,版圖大小有個物理上限,沒必要走極端)。
更重要的一點,切割版圖與找茬任務之間互不干擾,你改你的,我改我的。你改完了重新提交下一輪,也不影響我還在上一輪。中間也不用因為等待而停工。
切割版圖并合理分配資源的檢查方法,可以讓版圖設計師無需苦苦等待一臺計算機對單個大版圖各部分逐一檢查,而可以讓多臺計算機并行檢查同一張大版圖的不同部分,并自動匯總結果。這樣一來就能更快地完成任務。
版圖、原理圖對比與設計規則檢查同屬檢查類任務,都是以模塊為單位,本質上是數據對比工作、重內存需求、子任務間沒有數據關聯,是一種高并行度任務。因此這一階段很適合在云上使用內存優化型資源,通過暴力堆資源的方式快速完成任務。
模擬電路王冠上的明珠--射頻電路
射頻芯片作為模擬電路王冠上的明珠,一直被認為是芯片設計中的“華山之巔”。
一方面因為射頻電路的物理形狀和周圍介質分布會對射頻信號的傳輸造成很大影響,因此設計之路十分困難,前期需要進行大量仿真測試,而且為了保證高頻性能,材料的選取也十分講究,比如砷化鎵和氮化鎵。
另一方面,為了保證射頻芯片各類指標的性能均衡,很多指標的性能要求都需要挑戰工藝極限或設計創新性的電路結構,十分考驗工程師的經驗積累。
而射頻需要使用電磁場仿真,需要計算三維空間向量。
如果說版圖是將二維世界切成一片片的,那射頻就是將立體空間切成一粒粒的,當然更具挑戰性,算力需求也會呈指數級增加。
當遇到CPU無法滿足的情況,不妨嘗試使用GPU處理,他們可是處理向量計算的一把好手。
目前射頻電路電磁場仿真的三種常用軟件分別為:HFSS、EMX、ADS。
HFSS處理智能制造/汽車制造場景下的電磁場仿真較多、也支持部分芯片設計場景,EMX和ADS處理芯片設計場景的電磁場仿真更為廣泛。其中,HFSS和19版之后的ADS支持GPU處理電磁場仿真任務,且通過并行化處理后,效率提升十分顯著;EMX作為Cadence里的萬能插件暫不支持GPU任務。
關于計算量級的本質
單模塊、多模塊和top級任務是三種計算量級的任務,從字面上就能猜到單模塊任務,計算量最少;以此遞增,top級任務計算量最多。
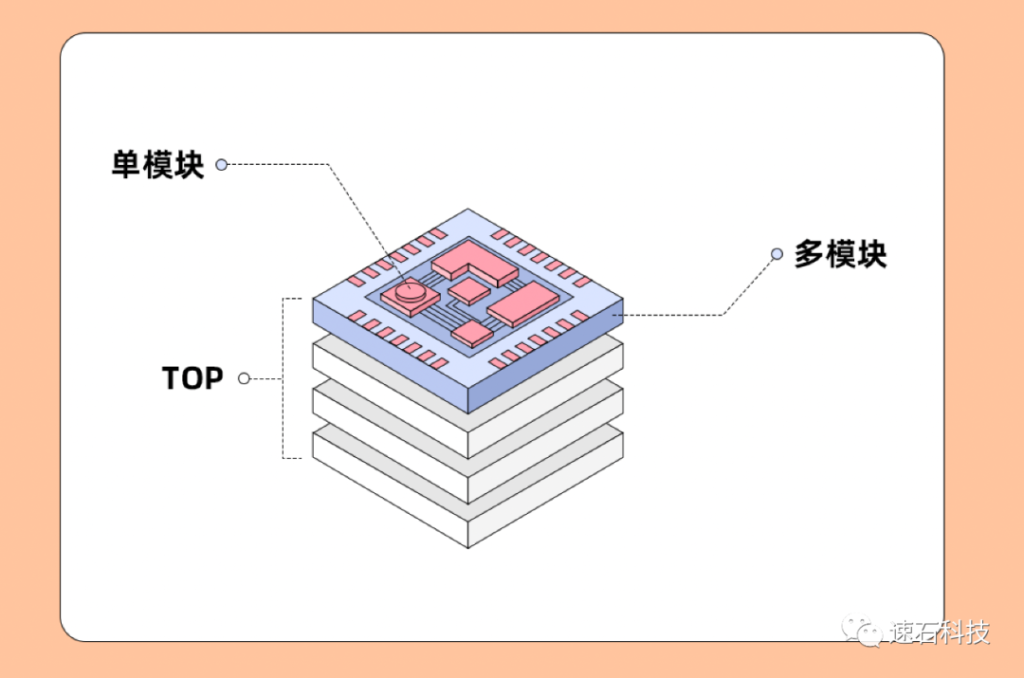
單模塊任務指的是單一模塊的任務,比如單層上的某個元器件就是一個單模塊任務,計算量級最小,可能可以繼續拆,也可能是最小不可拆分任務;
多模塊任務指的是多個單模塊合并在一起的任務,比如一層上的多個元器件組合在一起的模塊,計算量級中等,可將多個模塊拆分進行多線程處理;
top級任務,字如其名,是整個芯片設計階段最大規模的仿真,將整個芯片的全部功能模塊聚在一起,做全功能驗證。top級仿真是在頂視圖下的一整套前仿或后仿,算力需求最高。
如果涉及到先進工藝(28nm以下芯片),更小的空間,更多的模塊,更復雜的PDK工藝庫,計算量呈指數級增長。而且先進制程芯片后仿時還要做IR Drop的獨立性檢查,是SignOff的一個必要步驟。業內在該步驟使用的工具大多為Redhawk,和DRC/LVS的算法流程基本一致。
關于模擬IC設計,從不同設計階段的計算任務視角出發,我們總結了三點:
1、三大階段的算力需求呈現前期<中期<后期的趨勢。和波谷相比,峰值算力最高可達到百萬級別,使用彈性云端資源可以高效且動態地滿足峰值需求;
2、多corner、蒙特卡羅Monte Carlo以及DRC、LVS這類任務,非常適合直接用多機并行來提升任務效率;
3、基于單模塊不可拆的任務,雖不能做到多機分布式處理,但可以通過上大內存、高主頻機型,靠機器的性能實現任務效率的提升。
說到這,模擬IC篇就結束啦,敬請期待我們的第二集--數字IC!
關于fastone云平臺在其他應用上的表現,可以點擊以下應用名稱查看:
HSPICE │ Bladed │ Vina │ OPC │ Fluent │ Amber │ VCS │ MOE │ LS-DYNA│Virtuoso│ COMSOL
- END -
我們有個IC設計研發云平臺
集成多種EDA應用,大量任務多節點并行
應對短時間爆發性需求,連網即用
跑任務快,原來幾個月甚至幾年,現在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多電子書
歡迎掃碼關注小F(ID:iamfastone)獲取
你也許想了解具體的落地場景:
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化,3.5小時完成20萬分子對接
這樣跑COMSOL,是不是就可以發Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
5000核大規模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關于為應用定義的云平臺:
【ICCAD2022】首次公開亮相!國產調度器Fsched,半導體生態1.0,上百家行業用戶最佳實踐
解密一顆芯片設計的全生命周期算力需求
居家辦公=停工?nonono,移動式EDA芯片設計,帶你效率起飛
缺人!缺錢!趕時間!初創IC設計公司如何“絕地求生”?
續集來了:上回那個“吃雞”成功的IC人后來發生了什么?
一次搞懂速石科技三大產品:FCC、FCC-E、FCP
速石科技成三星Foundry國內首家SAFE云合作伙伴
EDA云平臺49問
億萬打工人的夢:16萬個CPU隨你用
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費4小時5500美元,速石科技躋身全球超算TOP500