
HFSS(High Frequency Structure Simulator)是世界上第一款商業化的3D電磁仿真軟件。
由Ansoft公司在1990年開發并發布第一個版本。
2008年,Ansys收購了Ansoft,繼續開發HFSS等電子與電磁仿真產品,目標是解決整個工業體系中機械與電氣領域的持續融合問題。
現在的HFSS,已經成為天線、射頻RF或微波組件、高速互連、濾波器、連接器、IC封裝、PCB設計者必不可少的工具。世界各地的工程師使用 Ansys HFSS 軟件來設計通信系統、高級駕駛輔助系統 (ADAS)、衛星和物聯網 (IoT) 產品中的高頻高速電子設備。

HFSS作為一款以麥克斯韋理論為基礎的數值仿真計算工具,如何摸準TA的特性,借助計算機技術有效提升仿真效率,我們今天淺聊一下。
01
擴展性低
大內存單機是首選
我們在藍箭航天案例中提到過,不同的CAE應用,對于底層資源的適配要求是不一樣的。
對于求解計算:
隱式算法,相對顯式算法來說,精度相對高。但可擴展性不是很好,即在多臺機器上的線性加速比并不好,適合在多核大內存機器上運行,一般對內存、IO要求比較高。
顯式算法,精度相比隱式算法低,但可擴展性更好,即在多臺機器上的線性加速比相對較好,適合于多節點并行計算,對機器無特殊要求,一般對內存、IO要求相對較低。
不同CAE業務場景的擴展性排序大抵如下圖所示,從上往下逐步提高:

HFSS作為計算電磁學的典型應用,在整個表的最上層,這代表其可擴展性低,適合高配、高IO的單機,性能越高越好。
這是由于兩方面原因造成的:
1. 網絡通信開銷大
2. 內存要求高
關于通信開銷,我們在Fluent實證和LS-DYNA實證中都提到過,隨著計算節點規模的增加,這兩個應用有著很明顯的節點之間數據交換造成的通信開銷,造成信息延時。
HFSS也是這樣,對網絡要求極高。隨著CPU核心數量的增加,帶寬優勢超過了核心效率。也就是說,堆機器不如堆網絡帶寬。
而在內存上的要求,跟算法、精確度十分相關,很大程度上取決于對需求與價格的取舍。
整體來說,HFSS對內存需求極高。根據我們的有限觀測,不同任務實際運行的CPU核數與內存比從1:5到1:23,差異巨大。單個任務對內存需求動輒幾百G,這類大內存機器放在整個行業都屬于稀缺資源。
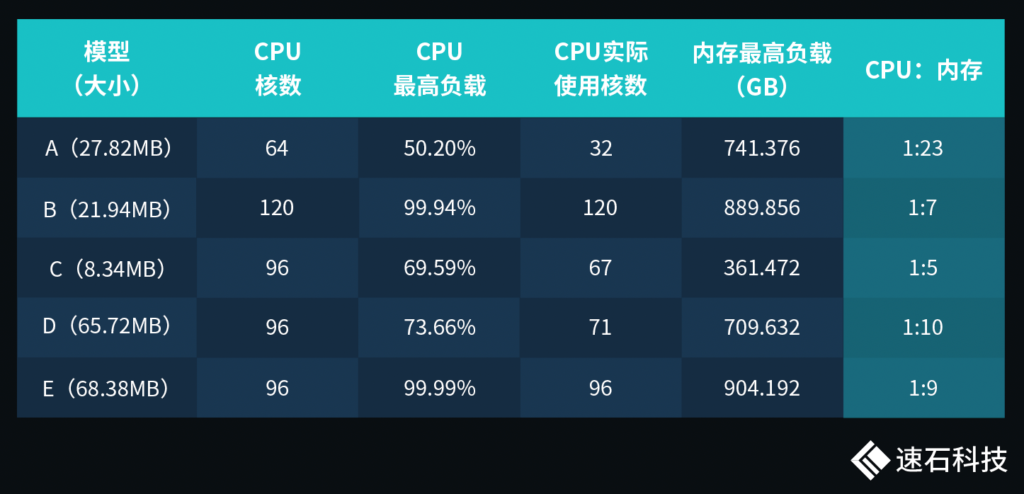
而結合以上這兩種需求場景,網絡要求高,內存需求大,單臺大內存機器成為不二之選。
我們全新推出的FCC-E專有D區配置水平如下:

四大特點:
1. 專供超大內存裸金屬機器;
2. 全新三/四代機器,性價比極高;
3. 三個月起租,短期/長期租賃皆可;
4. 可動態拓展至通用C區。
超大內存裸金屬機器,最大4T內存,最高192核,完美滿足HFSS應用需求。
單機多核心,帶寬不是問題。
內存足夠大,無需工程師向精度與算法做妥協。
而且,資源足夠,價格感人,還不用長期持有。
02
要是沒有大單機或者一臺不夠呢?
那就搞集群!
在過去,如果企業不購買成本極其高昂的大機器,工程師就不得不對規模和難度大的設計“拆分組合”處理,將幾何結構分割成多個區域,到后期再合并結果。由于沒有考慮所有的電磁耦合,這種方法是極容易出錯的。
或者,工程師直接簡化模型降低精度,以減少計算量。
現在,情況不同了,HFSS在HPC高性能計算技術方面下了不少工夫。
方法一:在算法層面的持續優化與改進,提供針對多核機器優化的數值求解器與算法;
方法二:通過將HFSS與調度器集成,將多臺機器組成集群來求解大規模問題,不再受限于單臺機器的配置水平,滿足網絡帶寬要求就可以。
這兩種方法,工程師都能使用HFSS求解更大、更復雜的模型,而不會影響精度。
我們擅長的是方法二。
對研發工程師來說,使用集群有兩大好處:
一、提高了單人使用上限
我們把一臺臺獨立的單機集群化,也就是變成一個統一的計算資源池。在某種意義上來說,集群可以被看作是一臺大的計算機,集群中的單個計算機通常叫做節點,由這些節點合作完成用戶任務。
當用戶把一個集群當一臺大計算機使用的時候,單個用戶的資源上限由原來一臺機器的上限,變成了這個資源池的整體上限。
所以,HFSS對資源的高要求,由原來的一臺機器變成由這個資源池來整體滿足。
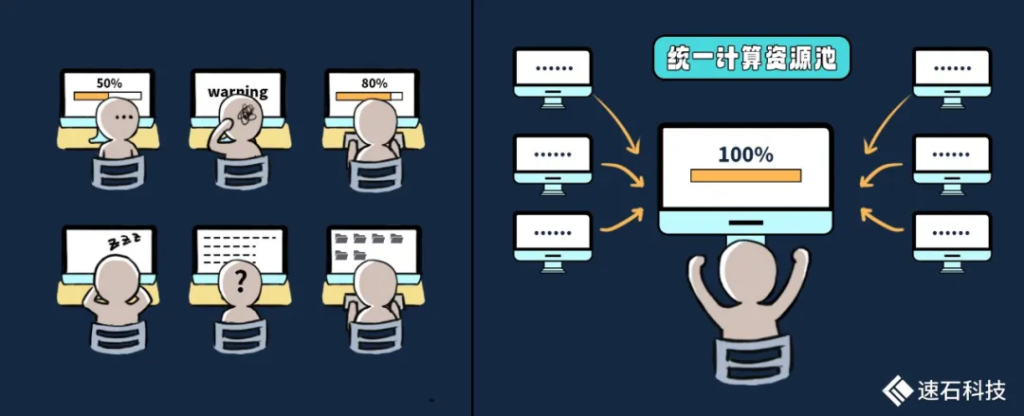
用戶可以將HFSS任務調度分布在多個計算節點上執行,也能通過在集群中劃分不同的仿真流程任務隊列及分配不同的資源隊列,并行執行多個CAE設計流程。
說人話就是,一個任務可以拆分多機跑,多個任務可以同時跑,來了大任務也不用擔心被一臺機器的上限所限制。
二、提高了團隊協作水平
單機模式下大家都是各用各的,缺乏協作,也沒有統一管理,無形中造成的溝通成本和損耗,其實并不小。
各種不同任務之間可能會出現資源爭搶,互相干擾。比如,兩個HFSS任務同時在一臺機器上跑可能出現內存告警。
而集群模式下:
我們根據不同業務團隊分工,為其在集群中劃分不同的獨立分區,這樣既保證了不同組的研發們能在同一個集群中工作,保留各自操作習慣,同時還互不干擾。
比如浙桂半導體的研發分為四個組,像元組的Sentaurus是搶資源大戶,往往他們的任務一上線,其他人就沒法用了。集群模式下的獨立分區可以很好地解決此類問題,戳這篇了解:【案例】95后占半壁江山的浙桂,如何在百家爭鳴中快人一步

同時,在建立起一套統一的使用規范基礎上,我們支持項目數據、用戶數據的統一管理和權限控制,不同業務團隊之間可以根據不同用戶權限共享計算、存儲、軟件資源等,整體上提高了整個團隊的工作與協同效率。
當然,除了研發工程師,對公司或團隊管理者和IT工程師來說,集群的好處就更多了。
這里不再展開,可以參考:從“單打獨斗”到“同舟共集”,集群如何成為項目研發、IT和老板的最佳拍檔?
03
絕配!
自適應網格剖分&Auto-Scale
一半時間畫網格,一半時間等仿真結果。
這恐怕是很多CAE工程師的日常。
HFSS的自適應網絡剖分技術,是在幾何結構和邊界條件網格自動生成的基礎上,根據電場梯度進行自適應網格細化和剖分,經過若干次迭代,給出滿足精度要求的結果。這一技術減少了求解所需的網格數量,大大降低了電磁場仿真的難度。
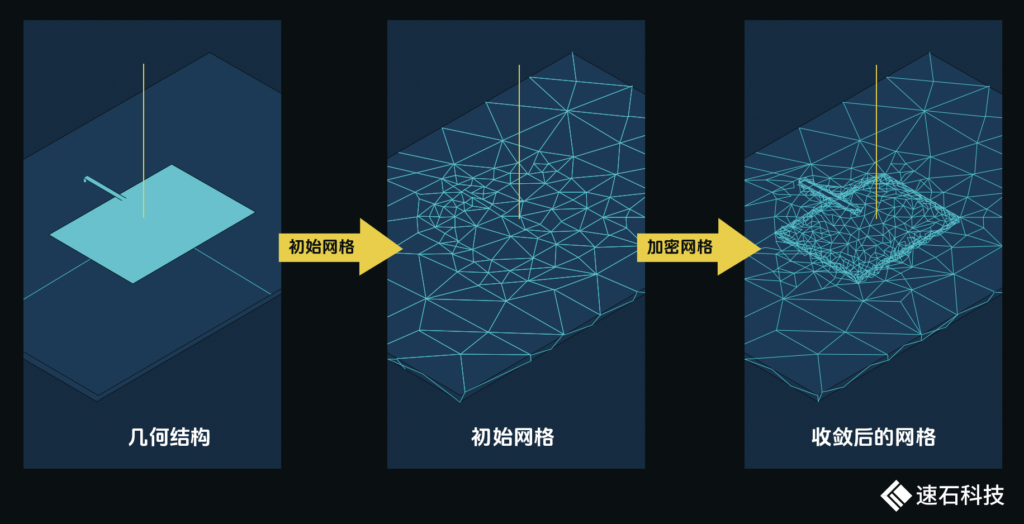
HFSS自適應剖分過程:自動生成初始網格,網格加密細化迭代,直到收斂。
整個過程完全自動化,無需人為干預。
這對廣大電磁場仿真工程師來說是非常大的利好,在減少工作量的同時降低了軟件的使用難度,讓工程師們可以將注意力完全放在如何得到好的仿真結果上。
接下來,讓我們換一個視角來看這個問題。
HFSS支持將整個自適應網格剖分過程通過調度器進行多步驟提交,我們的調度器Fsched提供的Auto-Scale功能與這個過程簡直是絕配。
最佳效果是分為三步:
第一步:初始網格生成,核數與內存需求很低;
第二步:網格自適應剖分,適度的核數與大量內存需求;
第三步:頻率掃描,核數與內存需求高。
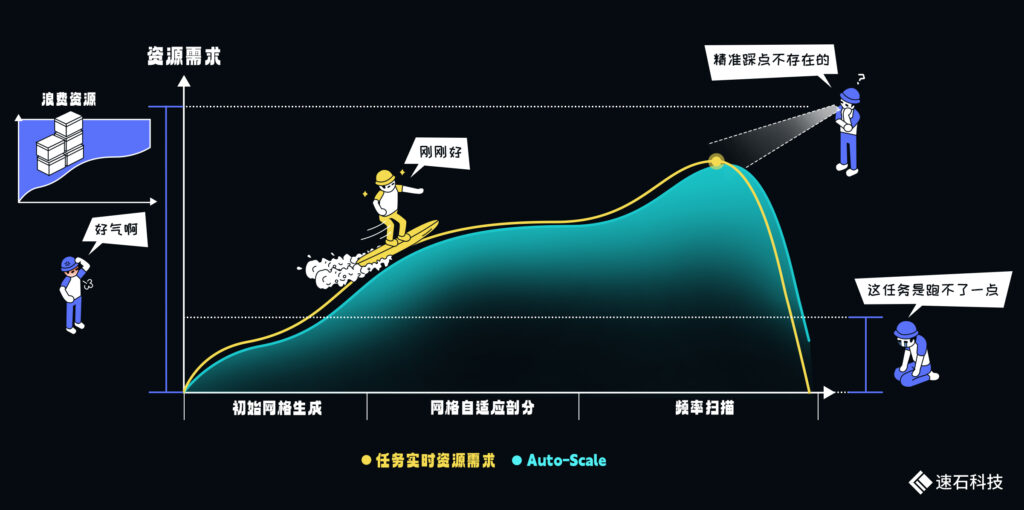
三個階段需要的資源量差別很大。
同時,由于這一過程是自動的,很難提前預估內存需求。
對用戶來說,如果留的緩沖空間比較大,可能造成資源浪費,留的空間小了,任務可能運行失敗。
我們的Auto-Scale功能可以根據HFSS任務在不同步驟的實際需求動態開啟云端資源,自動使用較少的資源啟動網格生成,而用較大的資源進行第三步頻率掃描,并在任務完成后自動關閉。
為每個步驟分配不同的資源量,最大程度匹配任務需求,提升任務成功率,減少資源浪費。
更多應用場景可戳:Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
04
GPU
一個可能的選擇
從ANSYS HFSS 17.2開始,HFSS開始明確支持GPU加速。
一般來說,GPU可以加速可視化和后處理過程,提高工作效率。
是否選擇使用GPU對求解器進行加速,主要還是取決于算法本身是否合適。
最新的ANSYS 2024 R1用戶手冊顯示GPU加速主要在以下三種場景:
1. 頻域求解器
2. 時域求解器
3. SBR+求解器

GPU加速需要占用HPC License,ANSYS Electronics HPC高性能選項模塊同時支持CPU加速和GPU加速,1個HPC Pack可以啟用1塊GPU加速卡或8個CPU內核。
綜合對比硬件成本與運算效率,目前業界普遍認為使用GPU跑HFSS性價比不高。
實證小結
1. 網絡通信和內存要求雙高,一般來說,用HFSS跑3D電磁仿真首選大內存單機
2. 沒有大內存單機或者一臺不夠的情況下,通過把HFSS與調度器集成,將多臺機器組成集群來求解大規模問題,能幫助用戶求解更大、更復雜的模型;
3. 自適應網格剖分技術結合fastone研發平臺的Auto-Scale功能可提升任務成功率,減少資源浪費。
本次CAE實證系列Vol.14就到這里了。
下一期,我們聊Abaqus。
關于fastone云平臺在各種CAE應用上的表現,可以點擊以下應用名稱查看:
Bladed │ Fluent │ LS-DYNA │ COMSOL
速石科技工業仿真行業白皮書,可以戳下方查看:
仿真宇宙|評測篇(上)|評測篇(下)
- END -
我們有個一站式工業研發平臺
CAE/CFD仿真設計全流程覆蓋
Auto-Scale自動按需開關所需資源
任務一鍵提交,仿真結果可視化
自研DM工具,高效傳輸仿真數據
仿真成本自動統計、分析、優化
掃碼免費試用,送200元體驗金,入股不虧~

更多CAE電子書
歡迎掃碼關注小F(ID:iamfastone)獲取

你也許想了解具體的落地場景:
從“地獄級開局”到全球首款液氧甲烷火箭,我們如何助力藍箭沖破云霄
光電兼修的Alpha Cen,如何應對上升期的甜蜜煩惱?
這樣跑COMSOL,是不是就可以發Nature了
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
一站式工業仿真研發平臺:
專有D區震撼上市,高性價比的稀缺大機型誰不愛?
從“單打獨斗”到“同舟共集”,集群如何成為項目研發、IT和老板的最佳拍檔?
國產調度器之光——Fsched到底有多能打?
研發/IT工程師雙視角測評8大仿真平臺,結果……
八大類主流工業仿真平臺【心累指數】終極評測(上)
2023仿真宇宙漫游指南——工業仿真從業者必讀
近期重大事件:
速石科技入駐粵港澳大灣區算力調度平臺,參與建設數算用一體化發展新范式
速石科技亮相第五屆中國仿真技術應用大會,領航工業研發云平臺發展
速石科技出席ICCAD2023,新一代芯片研發平臺助力半導體企業縮短研發周期
速石科技作為特邀服務商入駐IC PARK,合力打造集成電路產業新生態
速石科技聯合電信、移動、聯通三大運營商,為國家數字經濟轉型注入新動力


1、你們支持哪些應用/工具?
fastone工業軟件云平臺支持以下CAE/CFD應用:
Abaqus、Actran、Adams、Ansoft、Autodesk、AUTODYN、Bladed、CFX、COMSOL、CST、DYTRAN、Feko、FloTHERM、Fluent、HFSS、HyperWorks、ICEMCFD、Icepack、Isight、LS-DYNA、MARC、Matlab、MaxWell、Mechanical、Multiphysics、Nastran、nCode DesignLife、Numeca、OptiStruct、Patran、PowerFLOW、Q3D、Radioos、Simcenter、SimManager、Simpack、StarCCM、SOLIDWORKS、TOSCA、UX UG、VASP、WRF等。
此外,平臺還支持下列EDA應用:Innovus、Spectre、Genus、Dracula、Virtuoso、Ncsim、PowerSI、Xcelium、PT、DC、VCS、VC、FM、Verdi、OPC Proteus、Tmax2、HSPICE、Spyglass、Starrc、Calibre、Tessent、nmLVS、nmDRC、xACT、xL、xRC等。
還有這些AI框架:Pytorch、Mxnet、Tensorflow、Caffe2、Miniconda、Scikit Learn/OpenCV、Pylearn2、Keras等。
2、上述應用/工具是否都可以直接使用?
常用的應用/工具我們平臺都已經做過適配,并且做過一些優化。商用軟件因License授權不能直接使用,需要您BYOL(自帶License)。
3、跑Bladed,風文件和任務文件的數據量非常大,云端傳輸很慢,怎么辦?
我們有專門的數據傳輸工具DM(Data Manager),支持全自動化數據上傳,可充分利用帶寬,幫助用戶快速上傳、下載海量數據。同時,利用fastone自主研發的分段上傳、高并發、斷點續傳等數據傳輸技術,優化海量數據的傳輸效率。詳見《CAE云實證Vol.2:從4天到1.75小時,如何讓Bladed仿真效率提升55倍?》
4、那么大的數據,上傳或下載是否會有限制?
我們平臺不限制數據的上傳和下載大小,平臺接收數據不收費。
5、是否支持Fluent可視化的并行計算操作?
平臺支持Fluent在計算過程中的可視化監視操作,支持此類可視化監視的還包括CFX、StarCCM、Numeca、Matlab等軟件。
6、Fluent計算過程能否監視求解狀態?
支持,通過平臺的任務管理中的日志可隨時查看,狀態實時刷新。
7、Fluent計算過程能否監視求解殘差圖?
支持,在任務管理中可以顯示求解殘差圖。
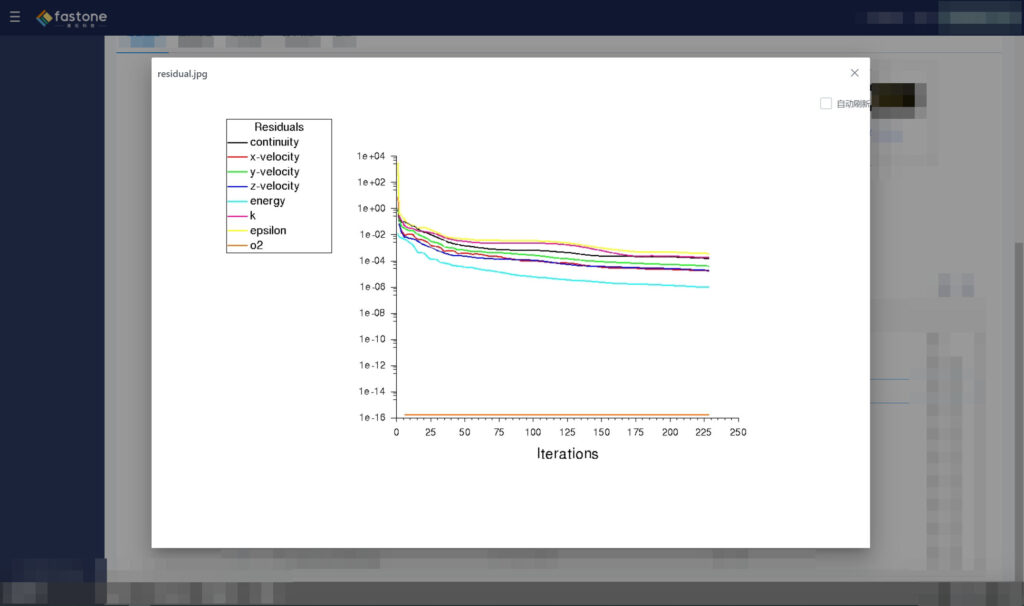
8、用你們平臺跑Fluent操作麻煩嗎?
fastone平臺可通過任務方式調度大量計算資源進行并行計算,處理Fluent任務。
如果您習慣使用圖形化界面操作,我們也提供圖形桌面,您可通過Web瀏覽器啟動集群,跳轉到虛擬桌面,并可在該桌面直接操作Fluent應用進行相應設置以開啟云端Fluent任務。
9、試過Fluent上云,一開始跑得挺快,但核數加上去之后,提升的速度反而降下來了,是怎么回事?
像Fluent和LS-DYNA這些應用,隨著核數逐漸增加,由于節點間通信開銷指數級上升,性能的提升會逐漸變緩。云端的網絡加強型實例可以有效解決這個問題。
詳請可查看《CAE云實證Vol.5:怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?》
《CAE云實證Vol.8:LS-DYNA求解效率深度測評│六種規模,本地VS云端5種不同硬件配置》
10、有時大半夜任務跑失敗了,第二天早上才發現,很浪費時間,是否有自動重復提交任務的功能?
放著機器通宵跑任務時總會幻想:第二天一早,任務已經跑完了,完美。
現實是:任務才跑了10%。
任務出錯,進度條卡住,可能會有兩種情形:
第一種:每個任務之間獨立,彼此沒有關聯。
一般任務數量越多,失敗的任務數量大概率也會變多。
第二種:每個任務間有明確的先后處理順序,必須從A任務按序跑到Z。
假如到F任務就失敗了,整個任務就此停滯,涼涼。
自動檢查任務狀態并對失敗任務及時重復提交的功能,就是這種場景的克星,尤其是第二種,不然等待著你的,大概就是通宵,同時睜大你的雙眼了。
我們的任務監控告警功能,還會時刻監控任務狀態,通過IM及時通知用戶,任務出現異常或已經完成。
舉一個其他行業出現過的特殊情況,Amber用GPU跑任務速度快,CPU較慢,但使用GPU計算時存在10%-15%的失敗概率。一旦任務失敗,需要調度CPU重新計算。
能否及時且自動地處理失敗任務,將極大影響運算周期。如果想了解我們怎么應對的,請查看《155個GPU!多云場景下的Amber自由能計算》
11、是否支持前處理、后處理的可視化操作?
可以,我們通過VDI集群的方式提供前處理、后處理的可視化操作。
12、你們平臺是否支持耦合計算?
支持,通過集群方式可以支持。
13、你們平臺提供哪些編譯庫?
我們提供包括 GNU、Intel、PGI在內的編譯庫。
14、你們平臺提供哪些并行計算框架庫?
包括 Intel MPI、OpenMPI、MPICH3、MVAPICH、MAVPICH2、OpenMM。
注:Intel 編譯器、Intel MPI、Intel MKL、Intel Vtune等為商業軟件。
15、你們平臺提供哪些GPU 庫?
我們支持 CUDA、OpenACC和OpenCL。
16、你們平臺提供哪些數學庫?
我們提供ACML、FFTW、OpenBLAS、MKL以及ScaLAPACK。
17、我們有些仿真軟件軟件在使用時需要GPU支持,你們平臺如何應對?
云上有很多類型的GPU實例,比如NVIDIA Tesla A100/V100/T4等GPU卡。針對有GPU計算要求的任務和應用,我們推薦使用GPU實例運行仿真軟件。
18、我們的仿真任務算完后,機器是不是會閑置造成資源的浪費?
建議使用我們平臺的任務模式進行仿真計算任務,任務結束后會自動保存結果數據,終止集群釋放資源,并郵件通知用戶任務計算完成。
19、你們是否提供Intel MPI支持?
平臺提供Intel MPI。
20、任務工作流并發數如何設置?
并發數設置需要綜合根據軟件特性與用戶實際需求,在小于開機核數的范圍內進行設置。
21、現在公司里才幾臺機器,天天維護頭就很大了,云上這么多機器還不得把自己搞禿了?
云上的運行環境都是自動化配置的,不需要人工干預,用戶還可以通過平臺進行統一管理和監控,方便易操作。
舉個例子,我們的Auto-Scale功能可以自動監控用戶提交的任務數量和資源的需求,動態按需地開啟和關閉所需算力資源,在不夠的時候,還能根據不同的用戶策略,自動化調度本區域及其他區域的目標類型或相似類型實例資源。所有操作都是自動化完成,無需用戶干預。
下圖就是開啟Auto-Scale功能后,用戶某項目一周之內所調用云端計算資源的動態情況。
其中橙色曲線為OD實例的使用狀況,紅色曲線為SPOT的使用狀況。

Auto-Scale功能可以根據任務運算情況動態開啟云端資源,并在波峰過去后自動關閉,讓資源的使用隨著用戶的需求自動擴張及縮小,最大程度匹配任務需求。
22、云上存儲是你們自己的產品嗎?與公有云上的存儲有什么區別?
答: 云上存儲可使用fastone Managed ZFS on Cloud或云原生存儲方案,云原生存儲方案可選EBS、云原生NFS及對象存儲。
23、存儲怎么收費呢?
冷存儲和熱存儲的費用是不一樣的,我們會根據用戶的情況提供個性化的解決方案。
24、數據備份的頻率如何?最高可以達到多少?現有策略怎樣?
默認每周六進行數據備份,也可以根據客戶需求按天或按小時備份。
25、使用平臺的工作人員比較多,能否對每個人設置使用資源的上限?
fastone平臺的權限和角色管理功能,支持管理員角色對每一個用戶進行相關權限設定,包括預算使用上限和CPU核數使用上限,從而在全局角度管控項目的資源消耗。該功能與智能預測配合使用,能夠從多個層面對預算和資源進行全方位規劃。

26、公司里還有些機器能用,你們支持混合云模式嗎?
支持。
可以將本地機器做成集群,也可以基于本地機器搭建混合云平臺。我們支持本地資源不足的時候,自動溢出到云上。
27、你們怎么實現混合云?
云資源和本地之間通過安全的數據通道連接,所有資源在fastone平臺統一管理,有統一視圖,并按需智能調度,不改變用戶的使用習慣。
28、公司里已經有機器了,再增加一套云環境,IT管理上會不會變麻煩?通過我們可以在不增加負擔的情況下對接多云,減少IT管理壓力。我們的自動化管理平臺很容易上手,對提升研發效率和資源利用率都有很大幫助。
29、我們公司有海外研發部門,用你們平臺方便嗎?
我們的平臺支持全球部署,我們會全球的優化組網,統一用戶管理,數據管理,優化的遠程接入方式,保持一致的用戶體驗。

30、云上云下的安全如何保障?
安全是一個立體的概念,包括系統安全、應用安全、流程安全、數據安全等很多方面。
云的基礎架構和傳統IT架構在安全方面并沒有本質上的區別,依然是利用計算節點和存儲資源。很多人覺得這兩者之間存在差異,我們認為這取決于個人的認知。本地的安全措施在云上都可以實現,同時云廠商本身還提供更強大的安全保障。
31、數據安全如何實現?
數據全部通過安全協議傳輸,并支持RBAC的數據訪問認證鑒權。同時,我們還支持數據加密存儲,算法可自定義。
32、你們有哪些落地實踐?
工業制造CAE跟云的結合,在全球幾乎已經是主流,所以它的單獨占比也相當高。而且現在國內CAE廠商,天然就是擁抱云的,甚至是云的推動者。
歡迎查看4個我們在CAE/CFD領域的合作案例:
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
LS-DYNA求解效率深度測評│六種規模,本地VS云端5種不同硬件配置
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
半導體EDA領域,如果結合云的落地場景來看,我們完全可以說國內跟全球站在同一起跑線上。
歡迎查看3個落地案例與2個針對不同規模IC設計公司的解決方案:
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
關于fastone云平臺在其他應用上的表現,可以點擊以下應用名稱查看:
HSPICE │ Bladed │ Vina │ OPC │ Fluent │ Amber │ VCS │ MOE │ LS-DYNA │ Virtuoso│ COMSOL
- END -
我們有個生物/化學計算云平臺
集成多種CAE/CFD應用,大量任務多節點并行
應對短時間爆發性需求,連網即用
跑任務快,原來幾個月甚至幾年,現在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多電子書 歡迎掃碼關注小F(ID:imfastone)獲取

你也許想了解具體的落地場景:
這樣跑COMSOL,是不是就可以發Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
5000核大規模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關于為應用定義的云平臺:
解讀Hyperion年度報告:脫離場景談用量就是耍流氓
這一屆科研計算人趕DDL紅寶書:學生篇
一次搞懂速石科技三大產品:FCC、FCC-E、FCP
AI太笨了……暫時
【2021版】全球44家頂尖藥企AI輔助藥物研發行動白皮書
國內超算發展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費4小時5500美元,速石科技躋身全球超算TOP500