
我們在今年年初的文章 【2021版】全球44家頂尖藥企AI輔助藥物研發行動白皮書 - 速石科技BLOG (www.youjiajingji.com) 白皮書里有聊到,對于AI,我們的判斷是現在主要還集中“人工”的部分,而不是“智能”。但CADD(計算機輔助藥物研發)/AI通常可以支持達到或選擇這些藥物研發工作的“更好”起點。
a16z的Vijay Pande博士在上周寫的文章《AI is Too Dumb… For Now》,同樣認為現階段的AI還是太“笨”了。如果人工智能不能變得比現在“聰明”很多,它在生物領域的潛力將是有限的。
Vijay Pande博士,a16z普通合伙人,主要專注于生物制藥和醫療領域的投資。
此前,Vijay是斯坦福大學的 Henry Dreyfus 化學教授,結構生物學和計算機科學教授,開創并一直在推動計算機科學技術在醫學和生物學領域的應用。他擁有300多篇出版物,兩項專利,兩種新型候選藥物。
那么,如果想要讓AI更加“聰明”,數據上,算法上,具體應該怎么做呢?
用“AI inside”替代“Intel inside”,對企業來說又意味著什么?
我們看看他怎么說的:
為了證明AI在生物領域的應用價值,我們走了很長一段路。
2018年,我還在《紐約時報》上爭辯:考慮到醫生的大腦很大程度更是黑匣子的前提下,圍繞醫學中人工智能“黑匣子”的恐懼到底有多不合理,以及未來的障礙和機會可能在哪里。
(注:這個爭辯背景是,有人提出沒有人知道那些高級AI算法到底是怎么學習的,過程過于黑箱,令人害怕。而Vijay說其實人類做決策很多時候是出于直覺,也不一定能說清背后的邏輯推理過程,本質上是個更大的黑箱。)
今天,已經有大量證據表明AI能掀起醫療和生命科學領域的革命(更不用說其他領域),甚至在一度被認為過于復雜而無法通過算法處理的一系列任務上表現得超越人類。
但是,盡管有了這些證據,現實中的現實是:如果人工智能不能變得比現在更智能,它在生物領域的潛力將是有限的。
AI可以被訓練(很像狗),但不能真正理解;它可以玩游戲,但僅限于已知規則;總之,它無法超越訓練本身。
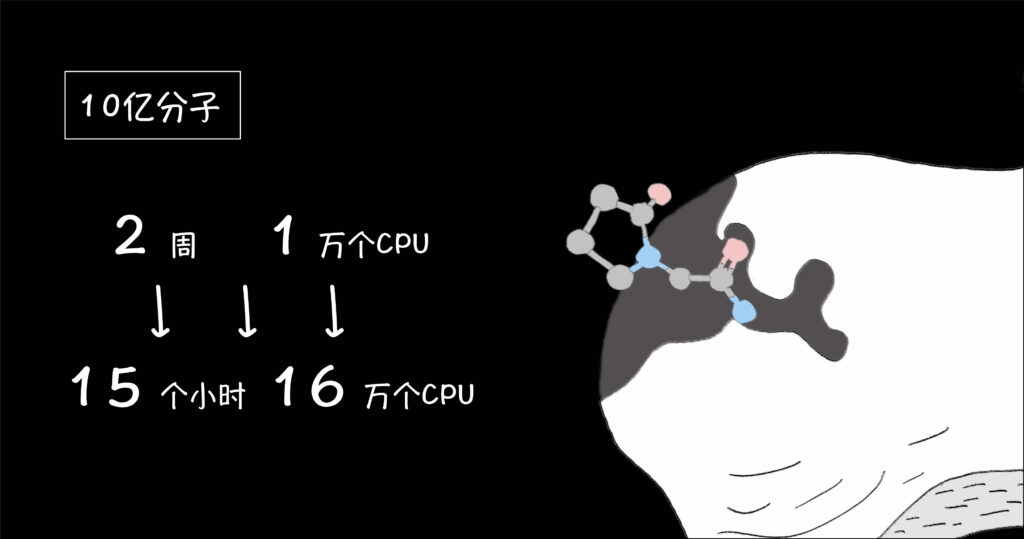
拿識別與致病蛋白質結合的小分子為例,人工智能能夠超出人類能力地加速和擴大藥物發現范圍,它必須從給定的訓練數據中推斷出物理規律(比如原子可以堆積多近)、化學規律(比如不同化學鍵的強度)和生物學規律(比如蛋白質口袋的靈活性)。但如果在任何方向上數據量過小,就會導致毫無意義的結果。 哈佛大學醫學院使用自研的VirtualFlow云平臺調用16萬核CPU對接10億分子花了15小時:《15小時虛擬篩選10億分子,《Nature》+HMS驗證云端新藥研發未來 - 速石科技BLOG (www.youjiajingji.com) 》
需要明確的是:我們所討論的不是一些類似于人類的科幻人工智能概念,也不是只有生物學才需要面對的“笨”人工智能挑戰。但是,由于需要大量行業專業知識才能理解問題的根源和提出可能的解決方案,在生物和醫療領域最能感受到依賴于這些樸素算法帶來的影響。
如果我們想在生物學和醫療領域更有意義地應用人工智能,并取得真正的進步,我們需要能夠創建具備行業專業知識的更“聰明”的AI算法。
那么,怎么才能做到呢?
對這個領域的玩家意味著什么?
一切從數據開始……
房地產行業的至理名言是“location,location,location”,而在人工智能領域,永遠是“數據,數據,數據”。
然而,現在的數據不太適合AI在生物學中的實際應用。探索這些數據可以得到一些零散的信息,但沒法得出普適性的生物學洞察。而且,這些數據也缺乏對AI學習內容和方向上的控制,無法避免數據缺陷。
為了讓人工智能在生物和醫療領域得到更實際和更廣泛地應用,需要通過自動化的方式生成數據。自動化的好處在于:更系統化,更可重復,不受人類情感約束,比如過于重復過于無聊。
但更關鍵的點在于如何設計實驗,需要在一開始就有針對性地為AI提供數據,從而確保更高質量的數據,規避數據缺陷。AI應該在開始數據收集之前就介入,這樣能更好地進行實驗設計,確定實驗路線。但很多時候,AI往往是在實驗快要結束的時候被硬塞進來的。
這跟科學家們之前受過的訓練完全不同,以前的實驗目標往往是驗證一個特定假設,而現在因為AI極大地擴展了可能性,為我們開啟了新世界的大門,讓我們可以擁抱那些我們不知道我們不知道的現實。
還是拿識別與靶標蛋白質結合的小分子為例(在初創公司和制藥企業中越來越常用的應用場景):
一方面,AI可以變得特別強大,尤其是當結果信息可以匯總,加強原來的數據,開始新一輪學習;
另一方面,AI可能會選擇一些違反科學家直覺的分子。以前,藥物化學家會根據經驗,對哪些修改會提高親和力和選擇性下一系列賭注,通常會排除他們“知道”行不通的選擇。而除了需要在計算機上進行大量天文數字模擬計算之外,AI不需要排除任何可能的修改,從而幫助藥物化學家擴大探索范圍,選擇應該制造和測試的分子。
這里就有一個虛擬篩選海量分子的案例,我們調用了10萬核CPU資源,花了15小時搞定了2800萬個分子:《生信云實證Vol. 生信分析上云案例, AutoDock Vina分子對接虛擬篩選 (www.youjiajingji.com)

這就是人工智能的力量——超越人類所能做的。當然,前提是它是“聰明”的,而不是“笨”的。
所以,到底如何讓AI更智能呢?
除了更高質量的數據,我們顯然還需要更優秀的算法。
1.升級算法
學彈吉他是件有挑戰性的事情,但對于會彈鋼琴的人來說則要容易得多(因為他們已經會看樂譜、操作一種樂器以及對音高和音調有敏感性)。我們可以將學鋼琴當成學吉他的“預訓練”。而在生物領域,預訓練看起來像是一種醫學轉錄算法,在使用醫學術語和分類學進行訓練之前,先使用英語語言和語法進行訓練。預訓練為AI提供了大量練習,教會它有關概念之間的關系,并且具有一些明顯可見的好處,比如加快以更少輸入實現更高準確度這個過程。預訓練的缺點是它仍然依賴于AI根據已知數據發現和推斷已知規則。
另一種方案是把行業專業知識直接編進算法里。這里的關鍵是以一種足夠通用的方式表示數據,讓它可以處理所有不同的排列組合。例如,在自然語言處理中,樸素AI以像素的形式輸入數據,然后將其翻譯為字母、單詞和句子等。使用更智能的編碼可以將文本顯示為字母,這樣可以大大減少訓練數據量,為數據貧乏的環境和更可預測的算法打開大門。在生物中,這可能意味著不再以體素(3D像素)的格式向AI描述分子,而是從包含了化學鍵信息的圖形開始,這意味著更大的化學空間。 讓數據表示包含更多目標信息是棘手的,必須經過深思熟慮,因為它可能變得非常清楚,也容易滑向反面,變得更加復雜難懂。
2. 面向行業應用而設計
當算法從一開始就面向某個特定生物應用進行設計時,它們也將變得更智能,同時能獲得行業專業知識。生物領域使用的很多AI技術都是直接從非生物應用中搬過來的;放射學中的算法與用于基本圖像識別的神經網絡類型是一樣的。
現在我們開始看到了針對生物學問題設計的算法和訓練的出現,像自監督算法的變體,它們從通用對應物開始,但結合了生物學見解來幫助學習。例如,了解細胞自然特征(染色質、細胞器等)的細胞成像算法可以讓我們更自然地使用自監督方法。這是因為數據更加一致(所有類型都相同,全都是細胞成像),并且圖像中的元素在沒有高級機器學習的情況下是眾所周知的(因為我們了解細胞的基本生物學)。這也將帶來更好的整體表現,并降低訓練數據量需求。
3.深入結合行業知識
最終,當算法與特定行業的計算方法成功融合時,它們將變得更智能,并提高適用性。
以分子動力學模擬為例,這是一種可以對分子物理和化學的許多方面進行編碼的強大計算方法,但它仍然依賴于以臨時、有偏見和依賴于人類判斷的方式完成的參數和訓練。通過將AI融入這些模擬計算中,可以使參數選擇更加穩健和可重復,帶來方法的整體改進。
在《生信云實證Vol.6:155個GPU!多云場景下的Amber自由能計算 - 速石科技BLOG (www.youjiajingji.com)》中,我們調用155個GPU進行基于分子動力學模擬的煉金術自由能計算。
未來,我們將基于AI模擬整個生物體。
綜上所述,所有這些都導致人工智能的“智能”發生翻天覆地的變化——從基于任務的簡單訓練(類似于訓練狗的特定技巧)轉變為需要更少訓練的更通用的智能,更自然地超出訓練本身(在科學范圍內),實現更準確的預測。
AI inside……意味著什么?
把“Intel inside”換成“AI inside”,對創業公司和老牌企業意味著什么?生物領域并不是第一個正在適應這種大轉變的行業。從華爾街到麥迪遜大道再到硅谷,每個人都在適應AI,我們能看到文化障礙與技術障礙幾乎一樣高。
對于一家生物公司來說,更實際和更廣泛地采用AI意味著將人工智能以及懂人工智能技術的人員將融入每個團隊,而不是一個通常在最后才被叫過來了解其他人做了些什么的獨立AI小組。這可能意味著企業需要配備在人工智能和生物領域“雙語”的人員,以及建立一種重視雙方的文化:渴望計算能力的生物學家和深深植根于生物領域的計算科學家。
眾所周知,改變根深蒂固的文化非常困難。
初創公司在這方面有明顯優勢,可以從0開始構建基于AI原生的團隊和思維方式。對于老牌企業來說,與其他創新一樣,領先的永遠是那些能夠調整傳統模式的公司。當然,他們也可以選擇建立全新的以AI為中心的團隊,讓這些團隊承擔越來越多的責任,從內部進行瓦解。

一種新的人才即將到來。
過去,“藥物獵人”是藥物化學家。但是隨著可以幫助完成機械重復工作和分子合成的CRO公司的興起,現在誰制造分子遠不如誰設計它們重要。隨著“量化分析師”的出現,我們看到金融領域就有類似的轉變,這些人更多擁有計算技能而不是對該領域專業知識。同樣的,這種轉變也將發生在化學和生物實驗室里。
到目前為止,這些生物“量化分析師”必須依賴大數據來支持他們的統計方法,由于成本和復雜性,現在還很難落地。但未來的智能算法能將他們的技能應用于小數據——從而應用到公司的所有領域。大數據是基礎設施和管線問題;小數據永遠是個智力問題,通過智能算法來解決,而不僅僅是靠聰明人。
正是這種能處理小數據能力的智能算法,將使AI無處不在。
與之前的其他重大技術轉變一樣,從樸素到智能 AI 的轉變將重塑整個組織結構,而不僅僅是與其最接近的功能。
為什么?因為更聰明的人工智能可以幫助回答曾經只屬于精明的人類判斷領域的關鍵業務問題。
太多人將人工智能視為生物制藥進步歷史長河中的下一個階段。
人們很容易把AI當成又一項技術進步,然而,這是一個過于狹隘的觀點,因為與其他技術不同,人工智能——尤其是這些智能算法——不僅是解決一個問題的工具,而且是可以應用于所有問題的工具。真正的力量不僅在于將其用作單一工具,還在于使用AI放大和整合公司中的所有工具和技術。
它不僅僅只是擺在桌面上的一個新盒子,而是我們在每個角色中的學徒和盟友。隨著人工智能無處不在,它將變得更聰明,我們也是。
我們基于全球44家頂尖藥企(包括3家中國藥企)在利用AI輔助藥物研發上的行動(共涉及55家AI初創企業、12家IT-云服務商、7所高校)制作了《【2021年】全球44家頂尖要求AI輔助藥物研發行動白皮書》,有興趣的可掃碼添加小F微信獲取。

- END -
我們有個為應用定義的云計算平臺
集成多種EDA應用,大量任務多節點并行
應對短時間爆發性需求,連網即用
跑任務快,原來幾個月甚至幾年,現在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多電子書歡迎掃碼關注小F(ID:imfastone)獲取

你也許想了解具體的落地場景:
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
5000核大規模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關于為應用定義的云平臺:
2小時,賬單47萬!「Milkie Way公司破產未遂事件」復盤分析
高情商:人類世界模擬器是真的!低情商:你是假的……
【2021版】全球44家頂尖藥企AI輔助藥物研發行動白皮書
EDA云平臺49問
國內超算發展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費4小時5500美元,速石科技躋身全球超算TOP500







