

1、你們支持哪些應用/工具?
fastone工業軟件云平臺支持以下CAE/CFD應用:
Abaqus、Actran、Adams、Ansoft、Autodesk、AUTODYN、Bladed、CFX、COMSOL、CST、DYTRAN、Feko、FloTHERM、Fluent、HFSS、HyperWorks、ICEMCFD、Icepack、Isight、LS-DYNA、MARC、Matlab、MaxWell、Mechanical、Multiphysics、Nastran、nCode DesignLife、Numeca、OptiStruct、Patran、PowerFLOW、Q3D、Radioos、Simcenter、SimManager、Simpack、StarCCM、SOLIDWORKS、TOSCA、UX UG、VASP、WRF等。
此外,平臺還支持下列EDA應用:Innovus、Spectre、Genus、Dracula、Virtuoso、Ncsim、PowerSI、Xcelium、PT、DC、VCS、VC、FM、Verdi、OPC Proteus、Tmax2、HSPICE、Spyglass、Starrc、Calibre、Tessent、nmLVS、nmDRC、xACT、xL、xRC等。
還有這些AI框架:Pytorch、Mxnet、Tensorflow、Caffe2、Miniconda、Scikit Learn/OpenCV、Pylearn2、Keras等。
2、上述應用/工具是否都可以直接使用?
常用的應用/工具我們平臺都已經做過適配,并且做過一些優化。商用軟件因License授權不能直接使用,需要您BYOL(自帶License)。
3、跑Bladed,風文件和任務文件的數據量非常大,云端傳輸很慢,怎么辦?
我們有專門的數據傳輸工具DM(Data Manager),支持全自動化數據上傳,可充分利用帶寬,幫助用戶快速上傳、下載海量數據。同時,利用fastone自主研發的分段上傳、高并發、斷點續傳等數據傳輸技術,優化海量數據的傳輸效率。詳見《CAE云實證Vol.2:從4天到1.75小時,如何讓Bladed仿真效率提升55倍?》
4、那么大的數據,上傳或下載是否會有限制?
我們平臺不限制數據的上傳和下載大小,平臺接收數據不收費。
5、是否支持Fluent可視化的并行計算操作?
平臺支持Fluent在計算過程中的可視化監視操作,支持此類可視化監視的還包括CFX、StarCCM、Numeca、Matlab等軟件。
6、Fluent計算過程能否監視求解狀態?
支持,通過平臺的任務管理中的日志可隨時查看,狀態實時刷新。
7、Fluent計算過程能否監視求解殘差圖?
支持,在任務管理中可以顯示求解殘差圖。
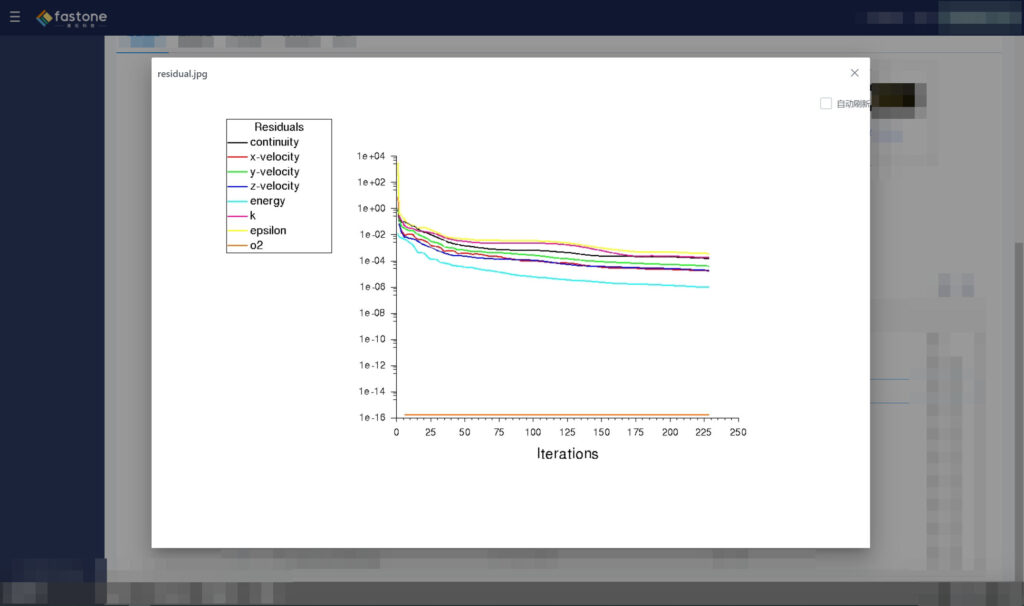
8、用你們平臺跑Fluent操作麻煩嗎?
fastone平臺可通過任務方式調度大量計算資源進行并行計算,處理Fluent任務。
如果您習慣使用圖形化界面操作,我們也提供圖形桌面,您可通過Web瀏覽器啟動集群,跳轉到虛擬桌面,并可在該桌面直接操作Fluent應用進行相應設置以開啟云端Fluent任務。
9、試過Fluent上云,一開始跑得挺快,但核數加上去之后,提升的速度反而降下來了,是怎么回事?
像Fluent和LS-DYNA這些應用,隨著核數逐漸增加,由于節點間通信開銷指數級上升,性能的提升會逐漸變緩。云端的網絡加強型實例可以有效解決這個問題。
詳請可查看《CAE云實證Vol.5:怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?》
《CAE云實證Vol.8:LS-DYNA求解效率深度測評│六種規模,本地VS云端5種不同硬件配置》
10、有時大半夜任務跑失敗了,第二天早上才發現,很浪費時間,是否有自動重復提交任務的功能?
放著機器通宵跑任務時總會幻想:第二天一早,任務已經跑完了,完美。
現實是:任務才跑了10%。
任務出錯,進度條卡住,可能會有兩種情形:
第一種:每個任務之間獨立,彼此沒有關聯。
一般任務數量越多,失敗的任務數量大概率也會變多。
第二種:每個任務間有明確的先后處理順序,必須從A任務按序跑到Z。
假如到F任務就失敗了,整個任務就此停滯,涼涼。
自動檢查任務狀態并對失敗任務及時重復提交的功能,就是這種場景的克星,尤其是第二種,不然等待著你的,大概就是通宵,同時睜大你的雙眼了。
我們的任務監控告警功能,還會時刻監控任務狀態,通過IM及時通知用戶,任務出現異常或已經完成。
舉一個其他行業出現過的特殊情況,Amber用GPU跑任務速度快,CPU較慢,但使用GPU計算時存在10%-15%的失敗概率。一旦任務失敗,需要調度CPU重新計算。
能否及時且自動地處理失敗任務,將極大影響運算周期。如果想了解我們怎么應對的,請查看《155個GPU!多云場景下的Amber自由能計算》
11、是否支持前處理、后處理的可視化操作?
可以,我們通過VDI集群的方式提供前處理、后處理的可視化操作。
12、你們平臺是否支持耦合計算?
支持,通過集群方式可以支持。
13、你們平臺提供哪些編譯庫?
我們提供包括 GNU、Intel、PGI在內的編譯庫。
14、你們平臺提供哪些并行計算框架庫?
包括 Intel MPI、OpenMPI、MPICH3、MVAPICH、MAVPICH2、OpenMM。
注:Intel 編譯器、Intel MPI、Intel MKL、Intel Vtune等為商業軟件。
15、你們平臺提供哪些GPU 庫?
我們支持 CUDA、OpenACC和OpenCL。
16、你們平臺提供哪些數學庫?
我們提供ACML、FFTW、OpenBLAS、MKL以及ScaLAPACK。
17、我們有些仿真軟件軟件在使用時需要GPU支持,你們平臺如何應對?
云上有很多類型的GPU實例,比如NVIDIA Tesla A100/V100/T4等GPU卡。針對有GPU計算要求的任務和應用,我們推薦使用GPU實例運行仿真軟件。
18、我們的仿真任務算完后,機器是不是會閑置造成資源的浪費?
建議使用我們平臺的任務模式進行仿真計算任務,任務結束后會自動保存結果數據,終止集群釋放資源,并郵件通知用戶任務計算完成。
19、你們是否提供Intel MPI支持?
平臺提供Intel MPI。
20、任務工作流并發數如何設置?
并發數設置需要綜合根據軟件特性與用戶實際需求,在小于開機核數的范圍內進行設置。
21、現在公司里才幾臺機器,天天維護頭就很大了,云上這么多機器還不得把自己搞禿了?
云上的運行環境都是自動化配置的,不需要人工干預,用戶還可以通過平臺進行統一管理和監控,方便易操作。
舉個例子,我們的Auto-Scale功能可以自動監控用戶提交的任務數量和資源的需求,動態按需地開啟和關閉所需算力資源,在不夠的時候,還能根據不同的用戶策略,自動化調度本區域及其他區域的目標類型或相似類型實例資源。所有操作都是自動化完成,無需用戶干預。
下圖就是開啟Auto-Scale功能后,用戶某項目一周之內所調用云端計算資源的動態情況。
其中橙色曲線為OD實例的使用狀況,紅色曲線為SPOT的使用狀況。

Auto-Scale功能可以根據任務運算情況動態開啟云端資源,并在波峰過去后自動關閉,讓資源的使用隨著用戶的需求自動擴張及縮小,最大程度匹配任務需求。
22、云上存儲是你們自己的產品嗎?與公有云上的存儲有什么區別?
答: 云上存儲可使用fastone Managed ZFS on Cloud或云原生存儲方案,云原生存儲方案可選EBS、云原生NFS及對象存儲。
23、存儲怎么收費呢?
冷存儲和熱存儲的費用是不一樣的,我們會根據用戶的情況提供個性化的解決方案。
24、數據備份的頻率如何?最高可以達到多少?現有策略怎樣?
默認每周六進行數據備份,也可以根據客戶需求按天或按小時備份。
25、使用平臺的工作人員比較多,能否對每個人設置使用資源的上限?
fastone平臺的權限和角色管理功能,支持管理員角色對每一個用戶進行相關權限設定,包括預算使用上限和CPU核數使用上限,從而在全局角度管控項目的資源消耗。該功能與智能預測配合使用,能夠從多個層面對預算和資源進行全方位規劃。

26、公司里還有些機器能用,你們支持混合云模式嗎?
支持。
可以將本地機器做成集群,也可以基于本地機器搭建混合云平臺。我們支持本地資源不足的時候,自動溢出到云上。
27、你們怎么實現混合云?
云資源和本地之間通過安全的數據通道連接,所有資源在fastone平臺統一管理,有統一視圖,并按需智能調度,不改變用戶的使用習慣。
28、公司里已經有機器了,再增加一套云環境,IT管理上會不會變麻煩?通過我們可以在不增加負擔的情況下對接多云,減少IT管理壓力。我們的自動化管理平臺很容易上手,對提升研發效率和資源利用率都有很大幫助。
29、我們公司有海外研發部門,用你們平臺方便嗎?
我們的平臺支持全球部署,我們會全球的優化組網,統一用戶管理,數據管理,優化的遠程接入方式,保持一致的用戶體驗。

30、云上云下的安全如何保障?
安全是一個立體的概念,包括系統安全、應用安全、流程安全、數據安全等很多方面。
云的基礎架構和傳統IT架構在安全方面并沒有本質上的區別,依然是利用計算節點和存儲資源。很多人覺得這兩者之間存在差異,我們認為這取決于個人的認知。本地的安全措施在云上都可以實現,同時云廠商本身還提供更強大的安全保障。
31、數據安全如何實現?
數據全部通過安全協議傳輸,并支持RBAC的數據訪問認證鑒權。同時,我們還支持數據加密存儲,算法可自定義。
32、你們有哪些落地實踐?
工業制造CAE跟云的結合,在全球幾乎已經是主流,所以它的單獨占比也相當高。而且現在國內CAE廠商,天然就是擁抱云的,甚至是云的推動者。
歡迎查看4個我們在CAE/CFD領域的合作案例:
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
LS-DYNA求解效率深度測評│六種規模,本地VS云端5種不同硬件配置
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
半導體EDA領域,如果結合云的落地場景來看,我們完全可以說國內跟全球站在同一起跑線上。
歡迎查看3個落地案例與2個針對不同規模IC設計公司的解決方案:
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
關于fastone云平臺在其他應用上的表現,可以點擊以下應用名稱查看:
HSPICE │ Bladed │ Vina │ OPC │ Fluent │ Amber │ VCS │ MOE │ LS-DYNA │ Virtuoso│ COMSOL
- END -
我們有個生物/化學計算云平臺
集成多種CAE/CFD應用,大量任務多節點并行
應對短時間爆發性需求,連網即用
跑任務快,原來幾個月甚至幾年,現在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多電子書 歡迎掃碼關注小F(ID:imfastone)獲取

你也許想了解具體的落地場景:
這樣跑COMSOL,是不是就可以發Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
5000核大規模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關于為應用定義的云平臺:
解讀Hyperion年度報告:脫離場景談用量就是耍流氓
這一屆科研計算人趕DDL紅寶書:學生篇
一次搞懂速石科技三大產品:FCC、FCC-E、FCP
AI太笨了……暫時
【2021版】全球44家頂尖藥企AI輔助藥物研發行動白皮書
國內超算發展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費4小時5500美元,速石科技躋身全球超算TOP500






