

LeDock是蘇黎世大學Zhao HongTao在博士期間開發的一款分子對接軟件,專為快速準確地將小分子靈活對接到蛋白質而設計。
LeDock優于大部分商業軟件,在Astex多樣性集合上實現了大于90%的構象預測準確度,對接時間最快僅需三秒。
LeDock同時支持Windows、Linux和MacOS三大操作系統。
Linux版支持大規模虛擬篩選,需要通過代碼操作才能實現目標。
Windows版的圖形界面極大簡化了藥物化學家常見多重復雜的對接過程,但每次任務只能對接一個分子,效率極低,只適用于少量對接場景。
如果考慮到不少用戶還有分子庫相關的需求,無論哪種版本,對用戶來說,都有點難搞。
今天我們就通過一個LeDock實證來聊聊,怎么幫助大家愉快地(不寫代碼)提高大規模分子對接效率(少點手動),甚至還能解決一些別的問題(一些爽點),擴大實驗的空間和范圍,放飛研發人員的想象力。
科研這件事,還是需要有點兒想象空間的。
用戶需求
某藥企藥物化合部想使用LeDock進行20萬分子對接任務,但本地只有兩臺48核的工作站。
如果按Windows版的一對一串行對接模式,假設按1分鐘一個算吧,不吃不喝不睡不關機,也要對接138天。如果再加上中間出錯修改、參數配置、分子庫處理,無數次重復手動操作步驟,就,沒法算了。。。
如果用Linux版,這一時長就取決于兩個點:本地擁有的資源數量和IT能力的高低。
所以,他們有以下幾個問題:
1. 基于現實條件,怎么快速達成用LeDock跑20萬分子對接任務這個目標?
2. 能不能使用更友好的圖形界面來進行操作?甚至把一些工作流程固定,下次直接就能用,還可以分享給同事?
3. 能不能幫忙準備分子庫?
實證目標
1、能否讓用戶擁有Windows版和Linux版的雙重優點,不用寫代碼,也能實現大規模虛擬篩選?
2、LeDock任務能否在fastone云平臺大規模運行且效率顯著提升?
3、用戶很多常見復雜的手動操作,能不能自動化進行?
4、是否能為用戶提供開箱即用的分子庫?
實證參數
產品類型:
速石FCC-E產品
操作系統及應用:
LeDock Linux版
適用場景:
研究配體和受體(藥物分子)相互作用的模擬方法
云端硬件配置:本任務屬于CPU密集型任務,對內存的需求不高,因此我們選擇了高性價比的云端計算優化型實例(CPU/內存=1:2)。
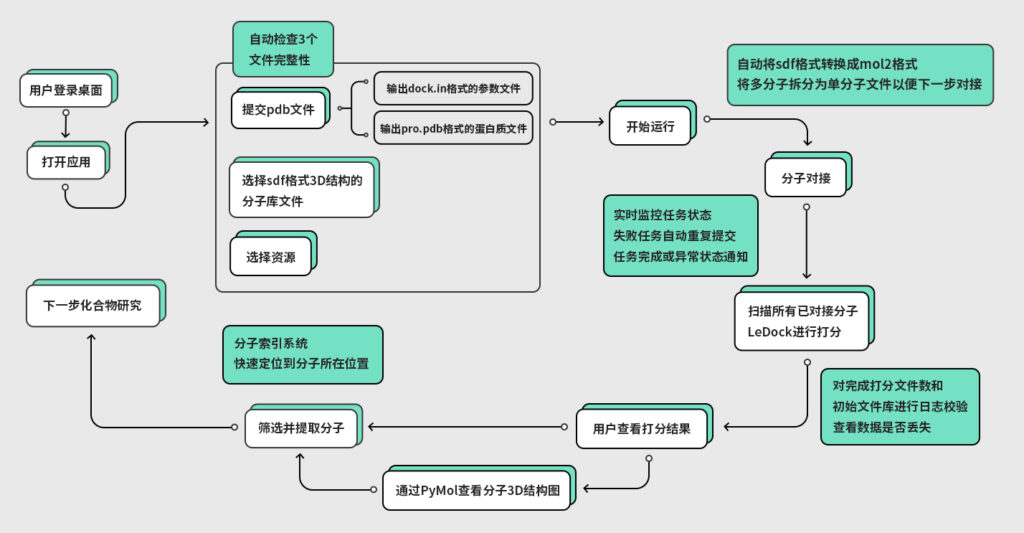
用戶完整工作流程圖
用戶打開應用,提交蛋白質pdb文件,選擇分子庫文件和資源后,由fastone平臺進行分子對接并打分,用戶可直接查看結果,提取目標分子,進行下一步化合物研究。
實證過程
一、開箱即用,一鍵定位&加密的分子庫
1. 開箱即用的分子庫
對接開始前,用戶除了蛋白質pdb文件,還需要準備分子庫文件。分子庫大多來自海外,其本身的大小和數據質量,直接影響著后續虛擬篩選階段的命中率。對用戶來說,需要將分子庫從外網下載到本地,有些數據量動輒幾十T,如果還涉及分子結構從2D轉換到3D等復雜處理,運算量相當大,要么耗時間,要么耗錢。
我們已經準備好開箱即用的分子庫供用戶使用,包括:Zinc、DrugBank、Maybridge、Enamine等。
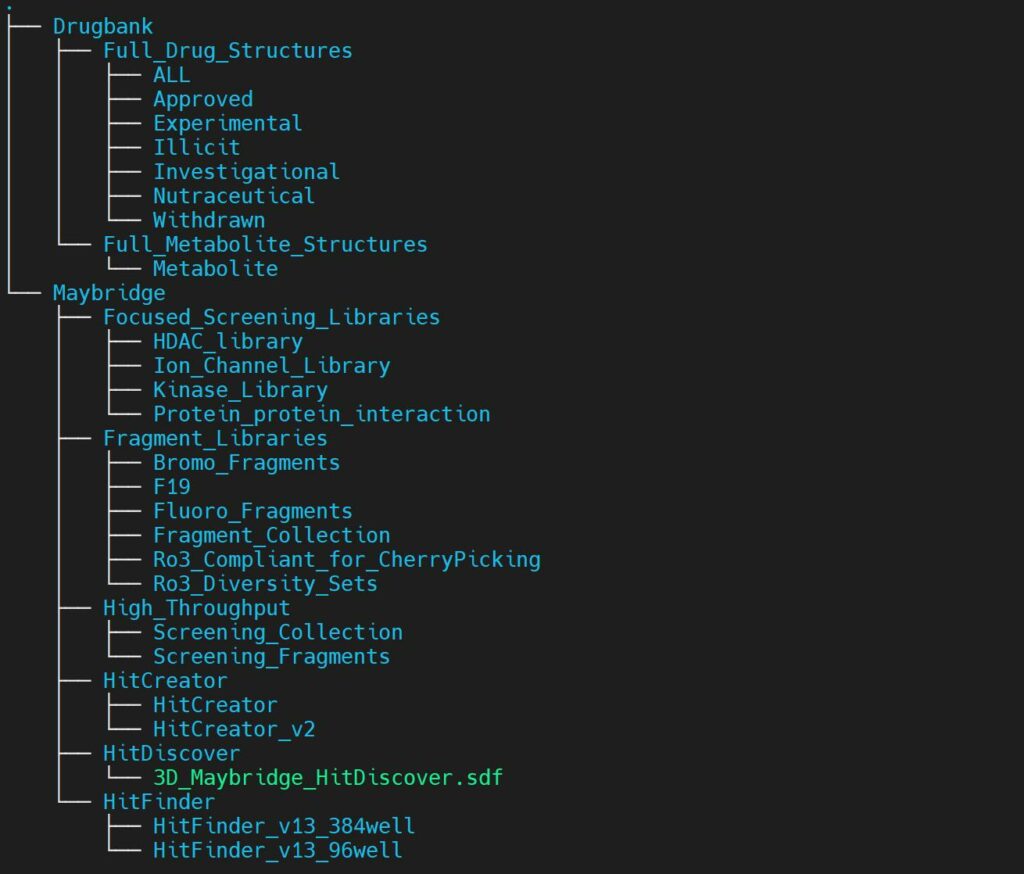
因為LeDock僅支持mol2格式,fastone平臺會在對接前,自動將sdf格式轉換成多分子mol2格式文件,同時完成拆分,使單個分子對應一個mol2文件。否則,直接把多分子mol2文件放進去對接,只會讀取第一個分子。
2. 一鍵定位&加密的分子庫索引系統
用戶篩選完分子后,還要在20萬個分子的原始庫里迅速定位并提取出來。這難度不亞于只知道書名但要在圖書館里找書,茫茫書海,大海撈針。
我們的分子庫索引系統就派上了大用場。
這套索引和圖書館索引系統類似,將原始分子名字通過加密轉換成唯一ID, ID相當于GPS定位,表示該分子在原始庫里的具體位置。
比如,某分子的唯一ID為“A-G22-18578”,即表示他位于分子庫A區G22柜的第18578個,可以輕松將分子提取出來。

這道索引系統相當于為原始分子庫做了一道數據加密和定位系統,除了用戶沒人知道最終提取出來的是哪些分子,既保護了數據的安全性,又讓用戶能迅速定位到某個分子。
二、云端大規模業務驗證
200000個分子上云
用戶使用fastone平臺,在云端調度768核計算資源,成功對接200000個分子,從中篩選出了300個分子,進行下一步的化合物研究。此次任務對接共耗時3.5小時,平均對接一個分子只需45S。
這里要說明一下,這個45S不是純分子對接時間,是包括了用戶的整個工作流程所有操作在內的。而且,不同分子之間的對接時長是不一樣的,時間會被對接得慢的分子拉長,無法直接橫向對比。比如用戶在進行3萬分子對接的時候,平均時長卻達到了90S。
實證過程:
1. 云端調度48核計算優化型實例運算一組LeDock任務(對接約200000個分子),耗時3262.6分鐘;
2. 云端調度96核計算優化型實例運算一組LeDock任務(對接約200000個分子),耗時1630.8分鐘;
3. 云端調度192核計算優化型實例運算一組LeDock任務(對接約200000個分子),耗時815.1分鐘;
4. 云端調度384核計算優化型實例運算一組LeDock任務(對接約200000個分子),耗時407.2分鐘;
5. 云端調度768核計算優化型實例運算一組LeDock任務(對接約200000個分子),耗時203.3分鐘。
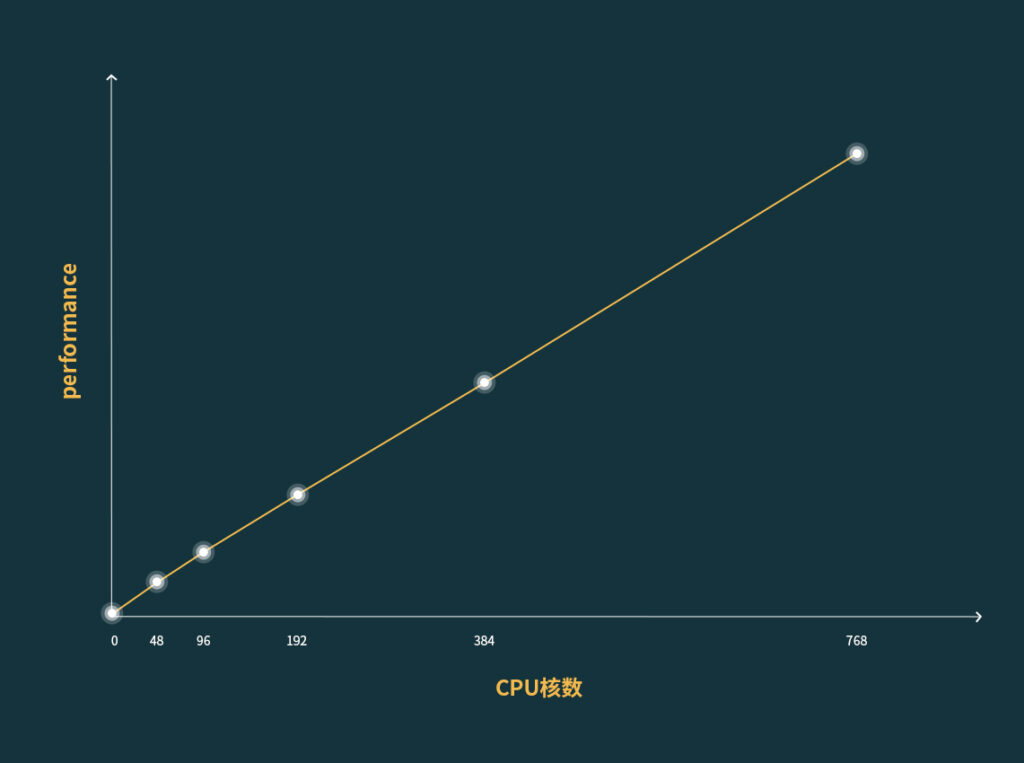
從圖上可以看出,LeDock任務在云端的線性擴展性表現良好,當云端資源增加到768核之后,運算時間縮短到了3個多小時,極大地提升了運行效率。
即使當分子數量增加到2800萬這個量級,我們調用10萬核CPU資源,在AutoDock Vina這個應用上也同樣表現優秀,可參考《提速2920倍!用AutoDock Vina對接2800萬個分子》
三、自動,自動,全是自動
1. 單機模式VS并行化
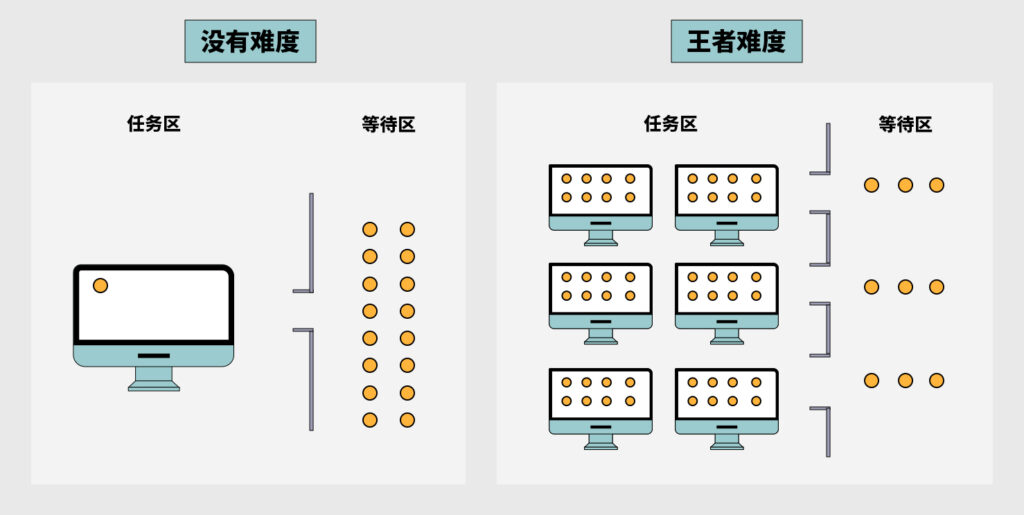
我們把跑分子對接這個任務分成三種不同的IT難度等級 :
沒有難度:單機單CPU核,單任務。
中等難度:單機多CPU核,多任務。
王者難度:多機多CPU核,多任務。
想要對三種難度等級深入了解,看這里《揭秘20000個VCS任務背后的“搬桌子”系列故事》
如果按照“沒有難度”這個等級,200000個分子串行排隊,一個任務跑1分鐘,我們開頭已經算過了,基本沒什么現實可操作性。
我們直接將你帶飛到"王者難度",在n臺n核的機器上跑,效率提升n*n倍,理論上n可以無限大。這個數字用戶可以自行設定。
2. 一次設定,跑完20萬個任務
怎么把一些工作流程固定,不用一次次重新設定,下次直接一鍵使用。甚至還可以分享給其他同事,提高大家的工作效率?
到了速石傳統藝能項目—自定義模板出馬的時候了。
我們將用戶跑LeDock的工作流程固定成一套模板:
step 1:用戶提交蛋白質pdb文件;
step 2:用戶選擇sdf格式分子庫文件;
step 3:fastone平臺自動將sdf格式轉換為mol2格式分子庫文件;
step 4:fastone平臺自動進行多分子拆分;
step 5:fastone平臺將蛋白質、參數文件與mol2格式分子進行對接;
step 6:fastone平臺掃描所有已完成對接的分子,進行打分;
step 7:用戶查看打分結果;
step 8:用戶篩選并從分子庫里提取出分子,進行下一步化合物研究。
用戶在這個模板的基礎上,自行調整各項參數,就能按這個流程一路跑下去了。
一次設定,反復使用,省時省力,還不用擔心以后不小心出錯。
這套自定義模板不但能分享,還可以跨應用設定,可以展開看看《1分鐘告訴你用MOE模擬200000個分子要花多少錢》
3. 自動檢查文件完整性
這個自動檢查包括兩個部分:
第一,用戶上傳配置文件的同時,速石平臺內置的檢查程序,會自動檢查文件完整性。
每個步驟需要用到的文件量很可能不一致,如果用戶運行到第五六步了,才發現某個上傳文件有問題,應該會非常崩潰。
第二,對接完成后,我們會對完成打分的文件數和初始文件庫做日志校驗,看數據是否有丟失。平常情況下,用戶可能很難察覺。
在這種大規模任務下,自動檢查程序能大大降低用戶任務返工率,以及協助用戶判斷運行過程中是否有問題。有些問題靠人力可能無力檢查。
4. 兩種場景下的重復提交任務功能和自動監控告警
放著機器通宵跑任務時總會幻想:第二天一早,任務已經跑完了,完美。
現實是:任務才跑了10%。
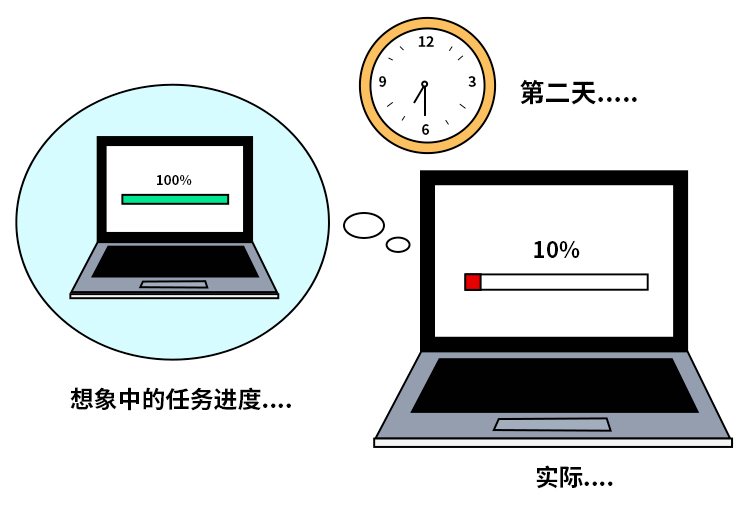
任務出錯,進度條卡住,可能會有兩種情形:
第一種:每個任務之間獨立,彼此沒有關聯。
一般任務數量越多,失敗的任務數量大概率也會變多,比如對接1萬個分子,有可能會有50個失敗任務;20萬個分子,可能有1000個失敗任務。
第二種:每個任務間有明確的先后處理順序,必須從A任務按序跑到Z。
假如到F任務就失敗了,整個任務就此停滯,涼涼。
自動檢查任務狀態并對失敗任務及時重復提交的功能,就是這種場景的克星,尤其是第二種,不然等待著你的,大概就是通宵,同時睜大你的雙眼了。我們的任務監控告警功能,還會時刻監控任務狀態,通過IM及時通知用戶,任務出現異常或已經完成。
我們還見到過一種特殊情況,Amber用GPU跑任務速度快,CPU較慢,但使用GPU計算時存在10%-15%的失敗概率。一旦任務失敗,需要調度CPU重新計算。
能否及時且自動地處理失敗任務,將極大影響運算周期。如果想了解我們怎么應對的,請點擊《155個GPU!多云場景下的Amber自由能計算》
實證小結
1、LeDock 大規模云端篩選毫無壓力,運行效率呈線性顯著提升;
2、fastone平臺能提供開箱即用,且能一鍵定位&加密的分子庫;
3、fastone 能為用戶定制自定義模板,一次設定,反復使用,界面友好;
4、fastone平臺提供的自動化檢查程序和重復提交任務功能,極大降低用戶的工作量;
5、用戶在20萬個分子對接任務中,篩選出了300個分子,進行下一步的化合物研究工作。
本次生信行業云實證系列Vol.12就到這里。
關于fastone云平臺在其他應用上的表現,可以點擊以下應用名稱查看:
HSPICE │ Bladed │ Vina │ OPC │ Fluent │ Amber │ VCS │ MOE │ LS-DYNA │ Virtuoso│ COMSOL
- END -
我們有個生物/化學計算云平臺
集成多種CAE/CFD應用,大量任務多節點并行
應對短時間爆發性需求,連網即用
跑任務快,原來幾個月甚至幾年,現在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創建集群
掃碼免費試用,送200元體驗金,入股不虧~

更多電子書 歡迎掃碼關注小F(ID:imfastone)獲取

你也許想了解具體的落地場景:
這樣跑COMSOL,是不是就可以發Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發性Fluent仿真計算縮短到4天之內?
5000核大規模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關于為應用定義的云平臺:
Uni-FEP on fastone|速石科技攜手深勢科技,助力創新藥物研發提速
【大白話】帶你一次搞懂速石科技三大產品:FCC、FCC-E、FCP






